Disk full outages rarely happen suddenly. In most cases, storage fills up slowly—logs grow, backups accumulate, temporary files stick around longer than expected. Then one day, writes fail, services crash, and you’re dealing with an avoidable incident.
Here’s the thing… preventing a disk full outage isn’t about adding more alerts. It’s about seeing the trend early enough to act before it becomes urgent.
Why Disk Full Issues Cause Real Downtime
When a disk reaches 100%, systems don’t degrade gracefully. Applications may stop writing logs, databases can fail transactions, and even basic OS operations can break.
But this is where it matters: disk issues are usually predictable. Storage usage tends to follow patterns, not spikes. That means you can detect disk full before failure if you’re looking at the right signals.
What Early Detection Actually Looks Like
Instead of waiting for a disk full warning in Linux at 90% or 95%, focus on growth patterns over time.
- Is disk usage increasing steadily every day?
- Did growth accelerate recently?
- Are certain directories responsible for most of the increase?
These signals tell you more than a threshold alert ever will.
Practical Ways to Detect Disk Full Before Failure
1. Track Disk Usage Trends
Run periodic checks and store historical data:
df -h
On its own, this isn’t enough. But if you log this daily, you can see whether you’re heading toward saturation.
2. Identify Fast-Growing Directories
Use tools like:
du -sh /* 2>/dev/null
This helps identify disk issues early by showing which areas are growing unexpectedly.
3. Watch for Log Accumulation
A common real-world scenario: logs growing unchecked.
For example, a service generating verbose logs after a minor bug can slowly consume gigabytes of space over days. No alert fires—until it’s too late.
4. Monitor Inode Usage
Sometimes the disk isn’t full—but inodes are:
df -i
This is especially common on systems handling many small files.
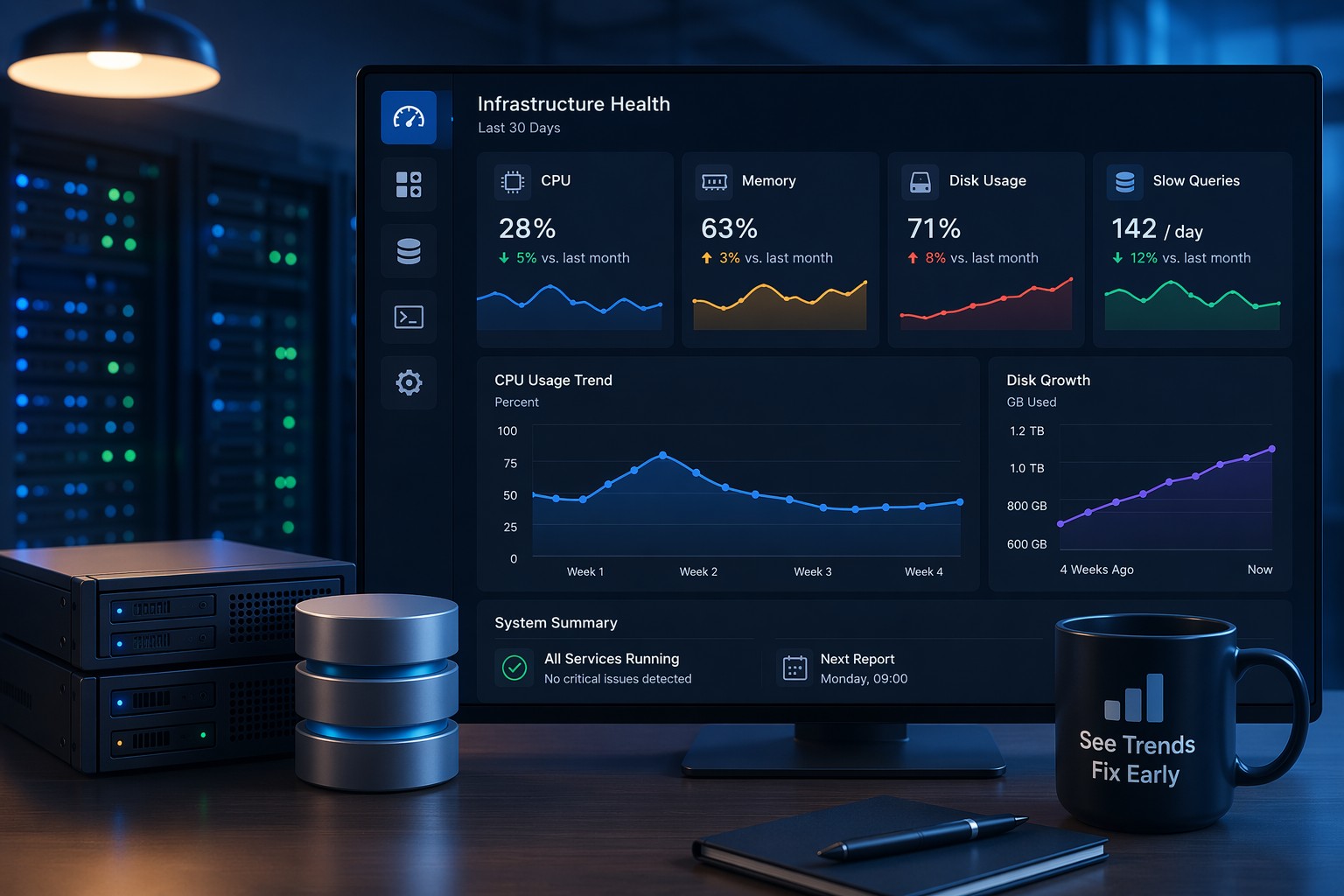
Real-World Example: The Slow Disk Leak
Let’s say your server has a 200GB volume. Everything looks fine until you check weekly reports:
- Week 1: 120GB used
- Week 2: 135GB used
- Week 3: 155GB used
- Week 4: 180GB used
No alert triggered yet. But the trend is clear—you’re heading toward a disk full outage.
So what does this mean in practice? You still have time to:
- Rotate logs
- Clean temporary files
- Expand storage
- Fix the root cause of growth
This is the difference between reactive monitoring and proactive health visibility.
Why Threshold Alerts Alone Don’t Work
Most monitoring tools rely on thresholds:
- 80% warning
- 90% critical
But by the time you hit 90%, you’re already in a time-sensitive situation. There’s little room for investigation or safe remediation.
Early detection isn’t about thresholds—it’s about understanding how your disk usage behaves over time.
Building a Simple Disk Health Approach
You don’t need a complex observability stack. A lightweight approach works well:
- Collect disk usage daily
- Track growth trends weekly
- Highlight abnormal changes
- Review system health regularly
This allows you to detect storage issues early in Linux environments without constant alert noise.
Summary
Disk full outages are one of the easiest problems to prevent—if you stop relying on last-minute alerts and start paying attention to trends.
When you can see how your storage is evolving, you can act early, fix root causes, and avoid downtime entirely.
If you want a clearer view of how your infrastructure behaves over time, take a look at Infrastructure Health Reporting. It’s designed to help you spot slow issues like disk growth before they turn into outages.