Linux Server Monitoring Checklist Before You Hire Backend or DevOps Help
Jul 08, 2026
Mariusz Antonik
Automation
6 min read
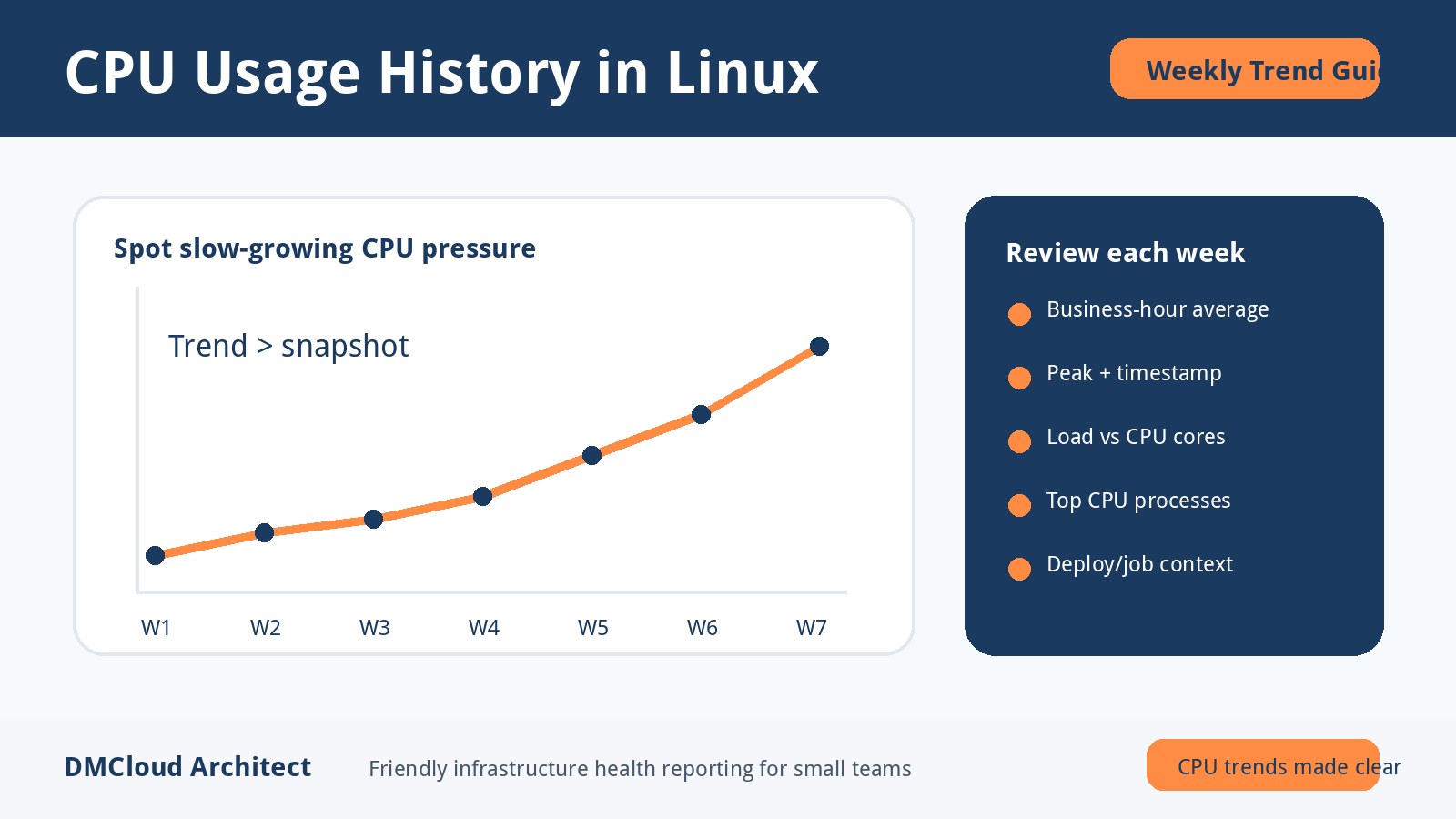
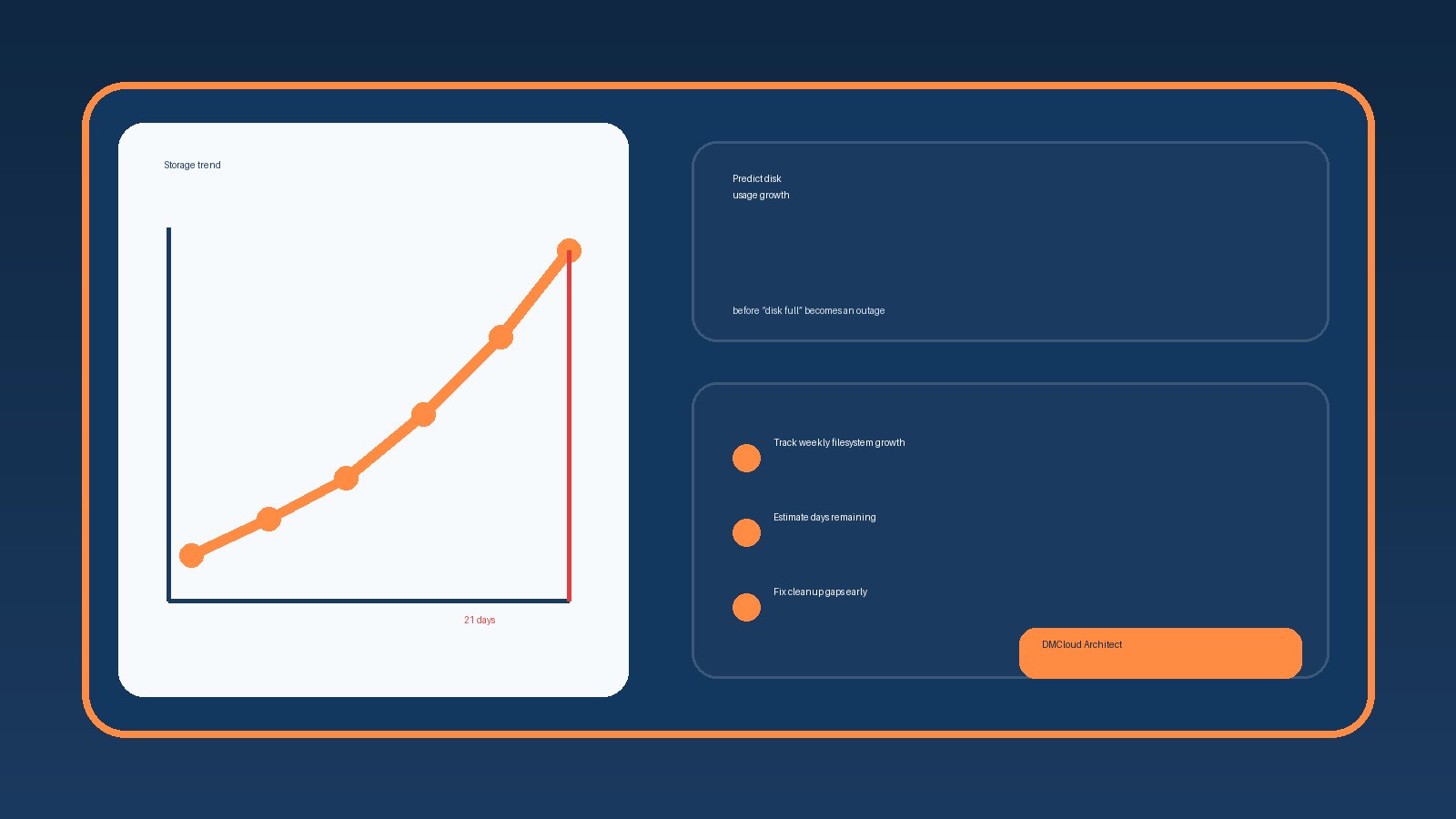
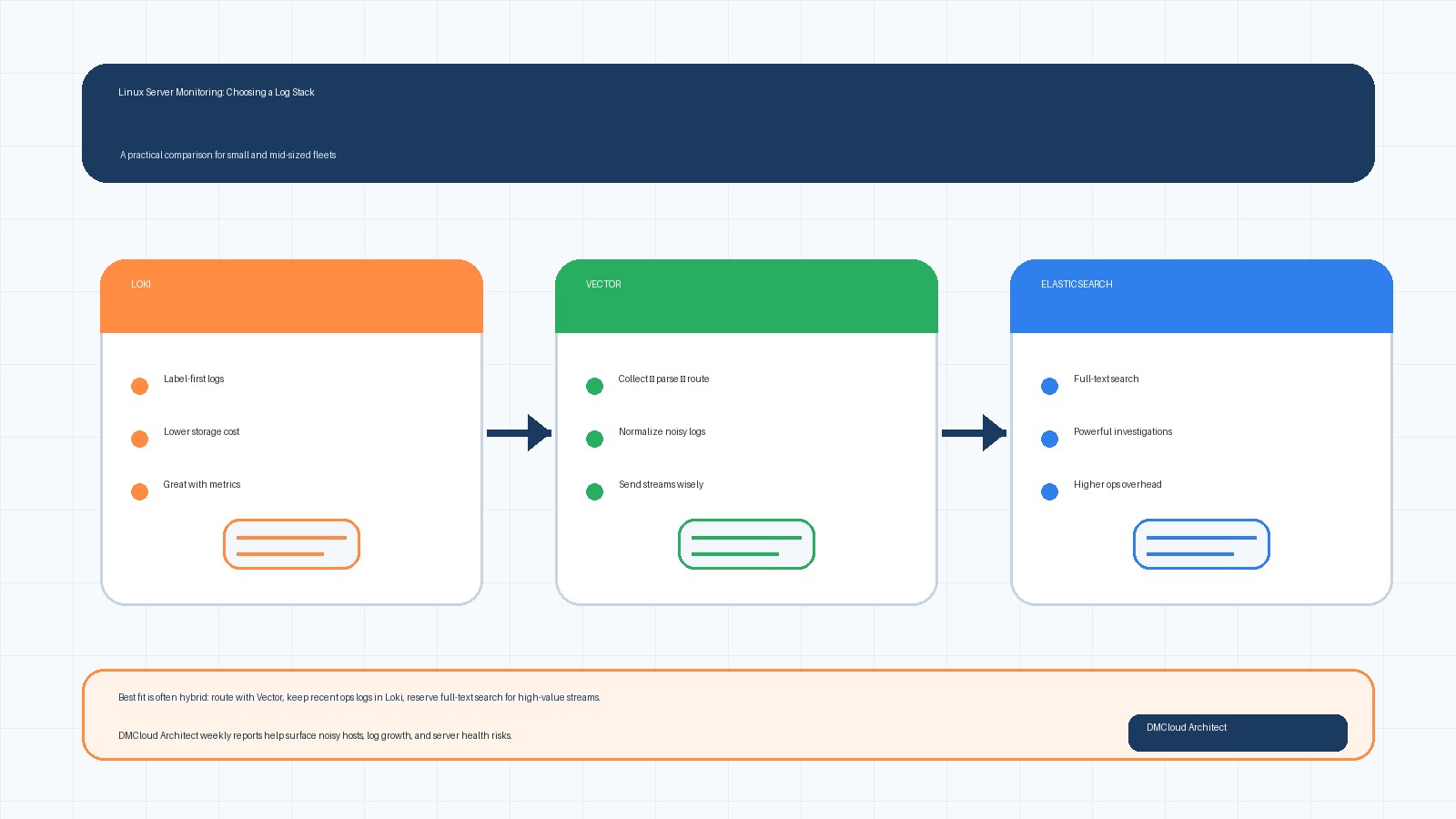
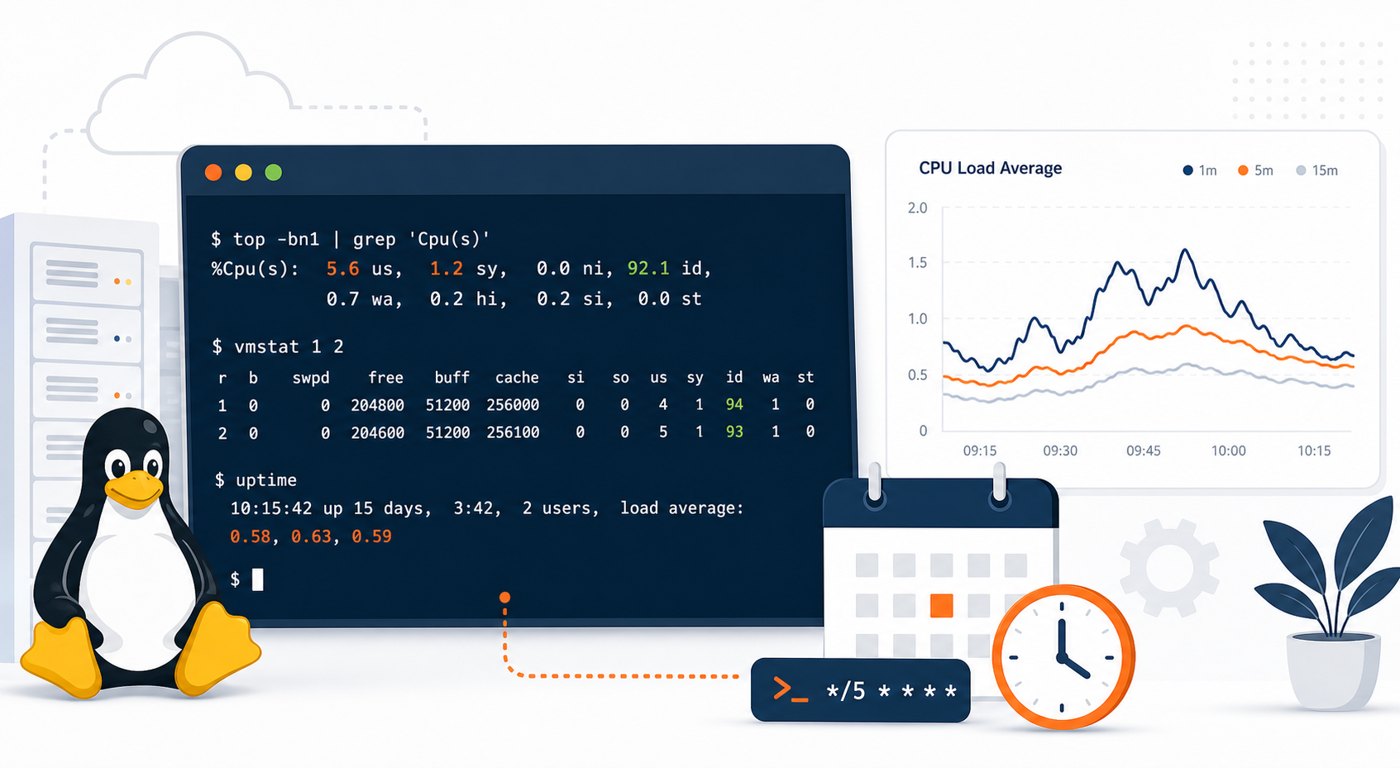
When a small team needs backend, DevOps, or AI infrastructure help, the fastest win is often better visibility into the Linux servers already running production. This checklist helps you separate urgent engineering work from routine monitoring gaps, so you can hire specialists for the right reasons. Use it to review CPU, memory, disk, logs, security, and backup signals before committing to a monthly engagement or a new dashboard project.
#backend-infrastructure
#devops-help
#infrastructure monitoring
#linux server monitoring
#server health
#small-business-tech
Read More