Create a Server in Oracle Cloud: Step-by-Step OCI Compute Instance Guide
Jun 16, 2026
Mariusz Antonik
Oracle Cloud (OCI)
2 min read
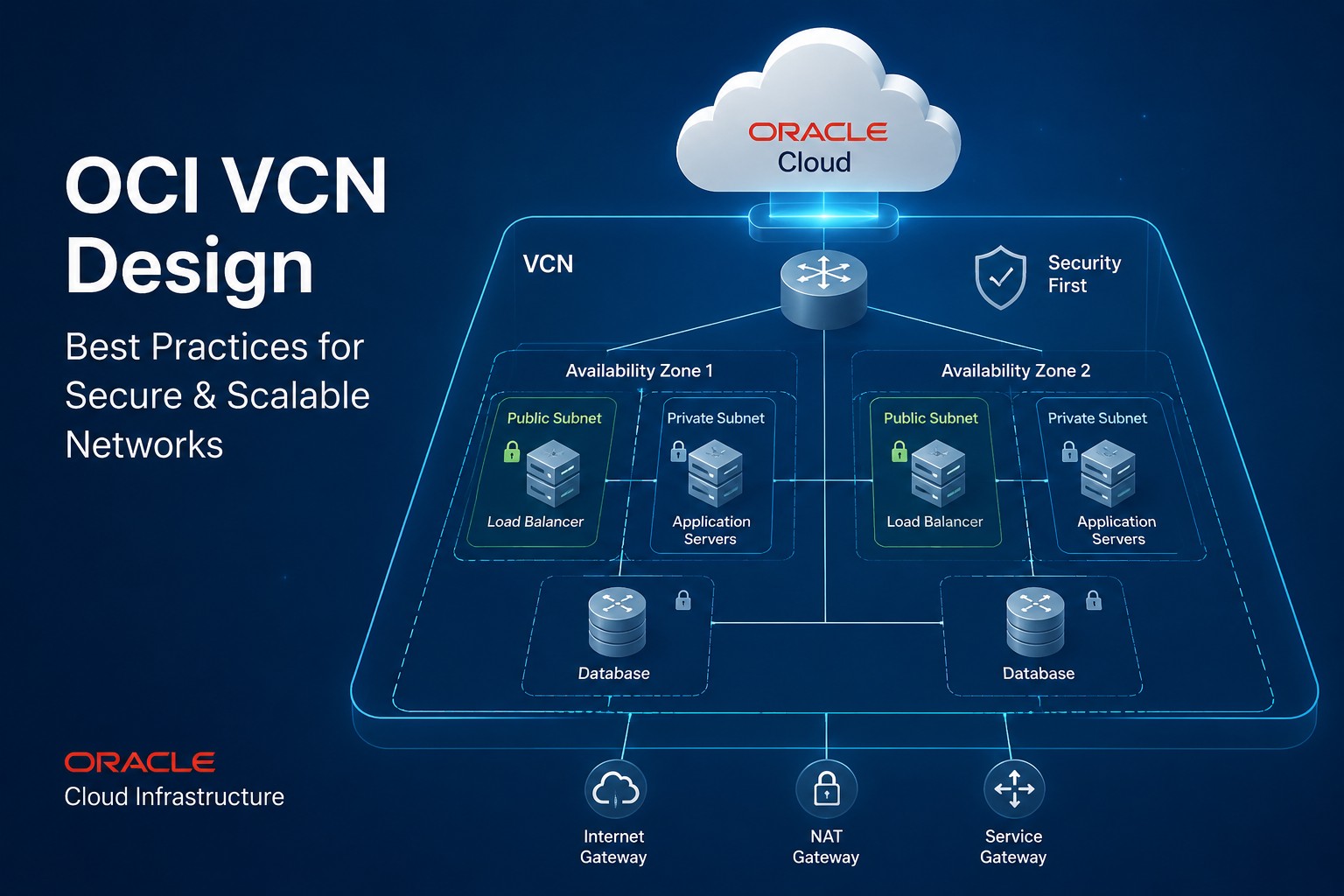
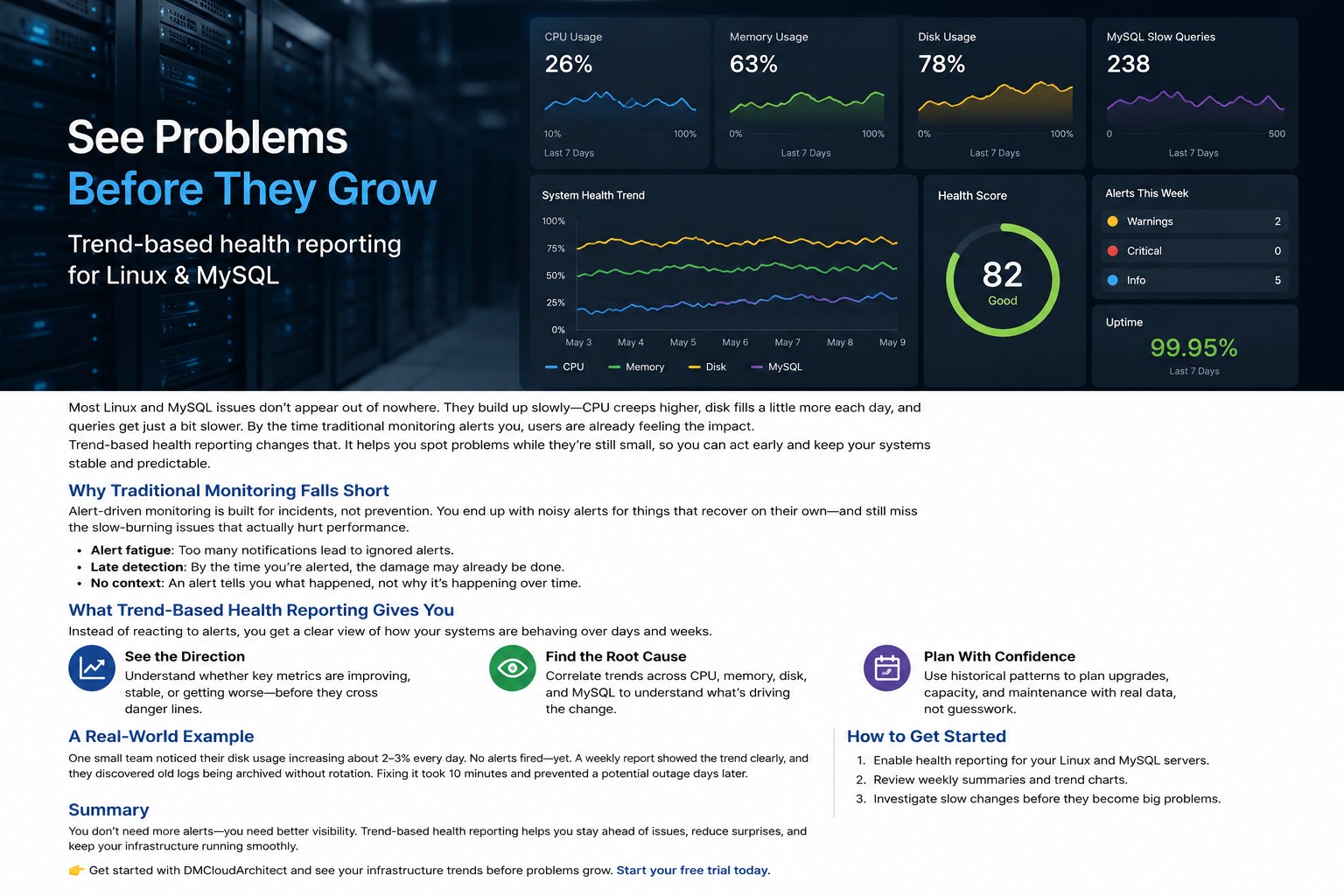
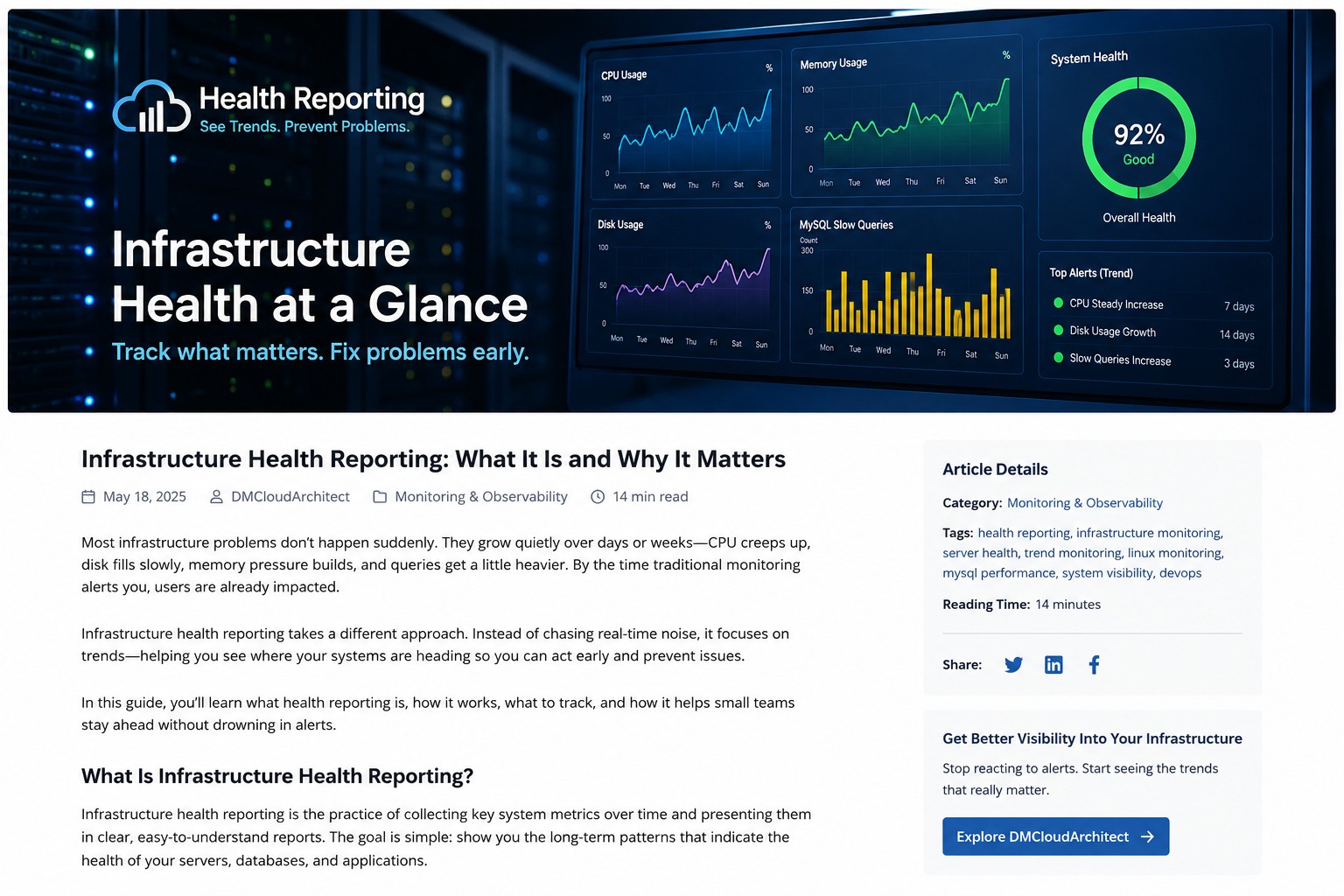
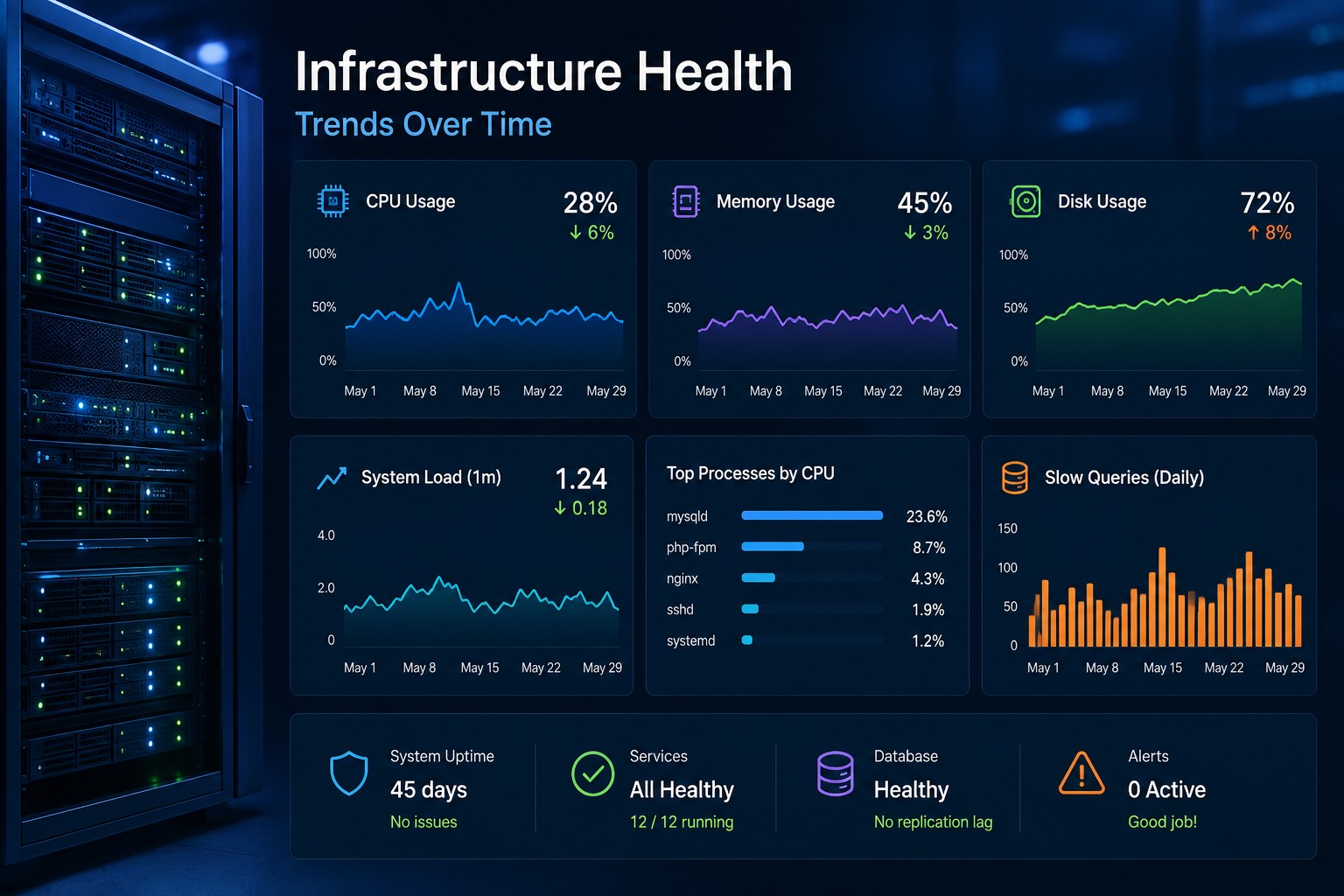
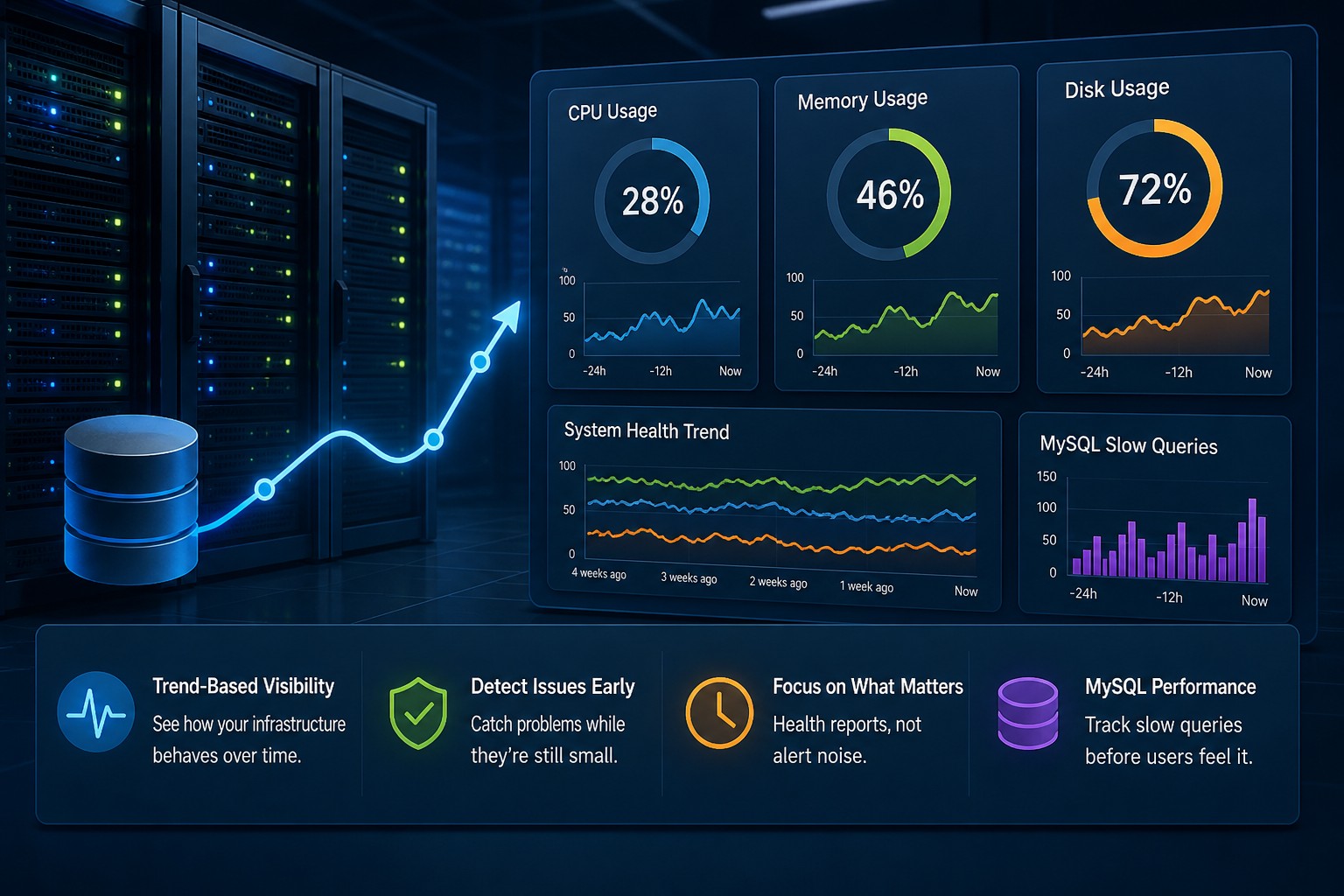
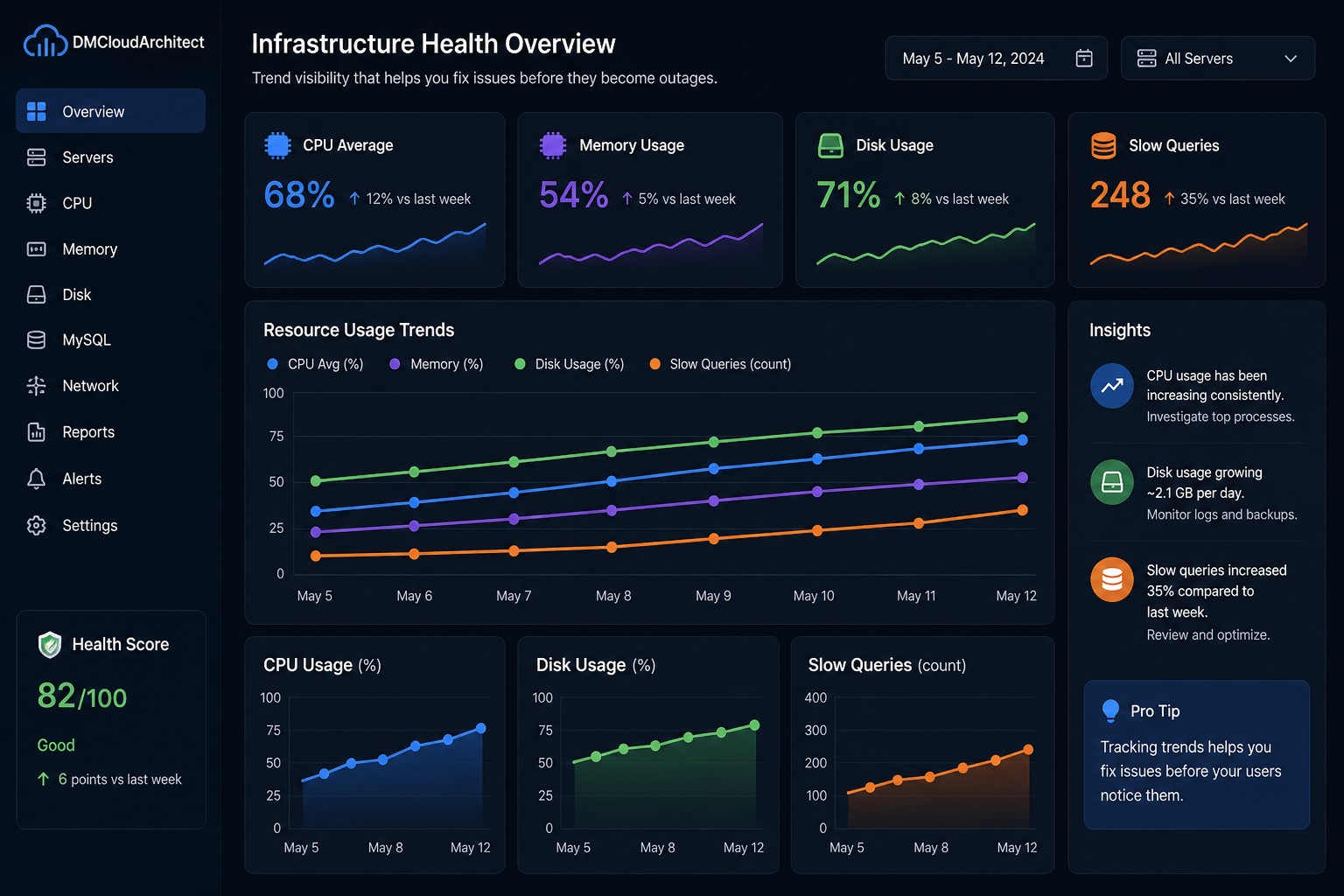
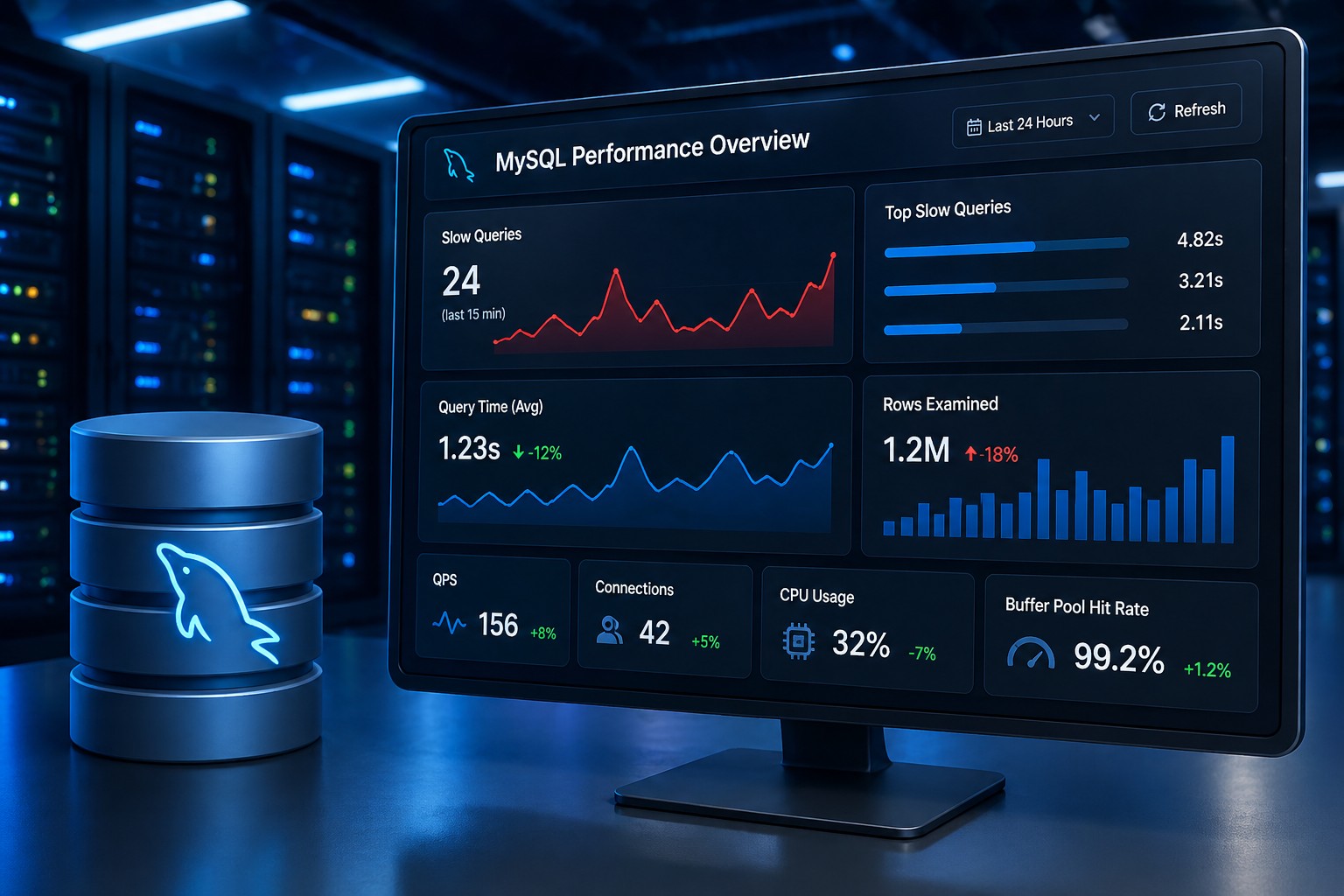
Creating a server in Oracle Cloud is one of the first and most important tasks when building on OCI. This guide walks through launching a compute instance, selecting the right configuration, securing access, and applying infrastructure best practices. You'll also learn common mistakes to avoid and practical recommendations for maintaining a secure environment. Whether you're deploying a test environment or production workload, this guide provides a solid starting point.
Read More