CPU Saturation Warning on Linux: Detect Trouble Before Slowdowns
May 23, 2026
Mariusz Antonik
Server Health
3 min read
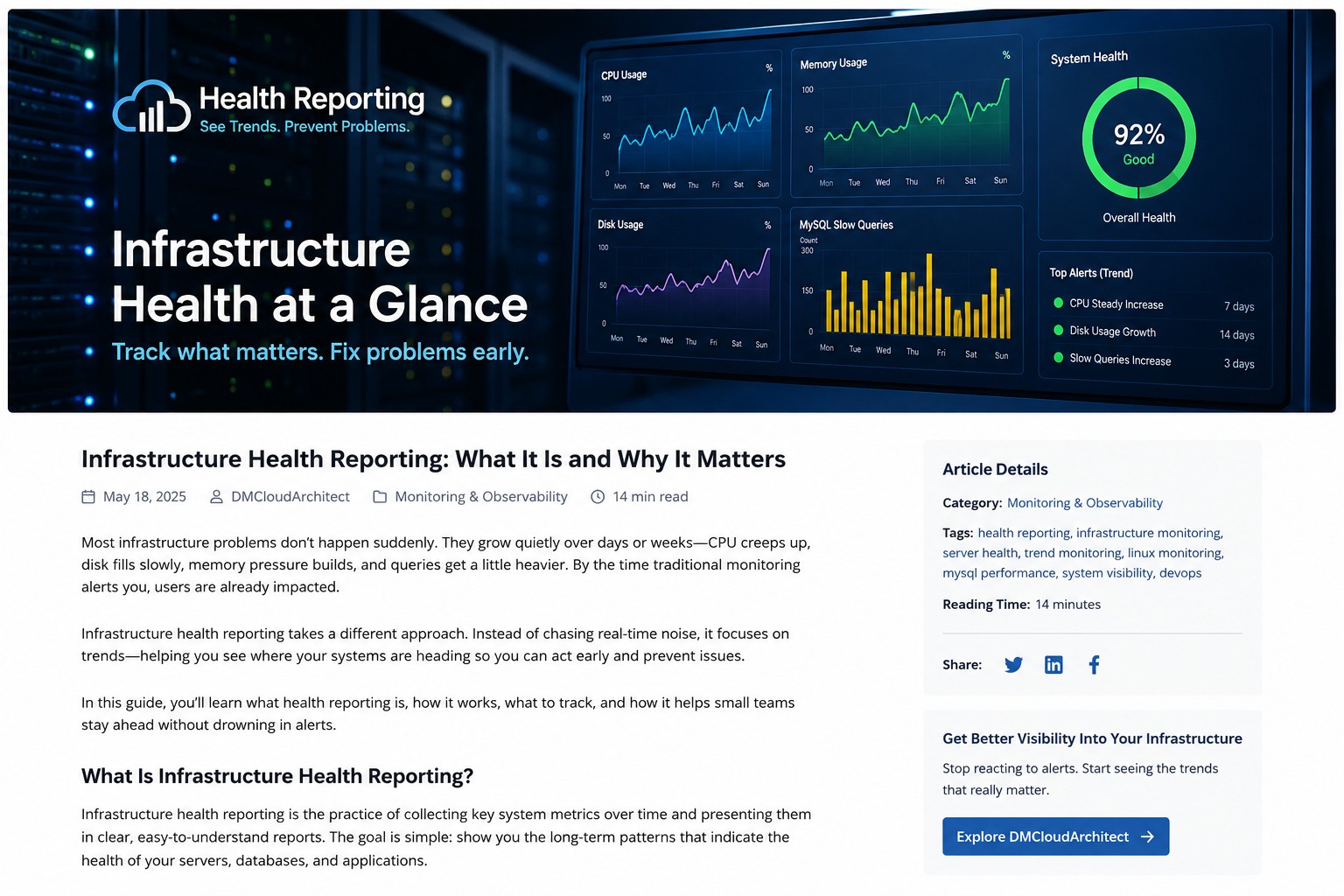
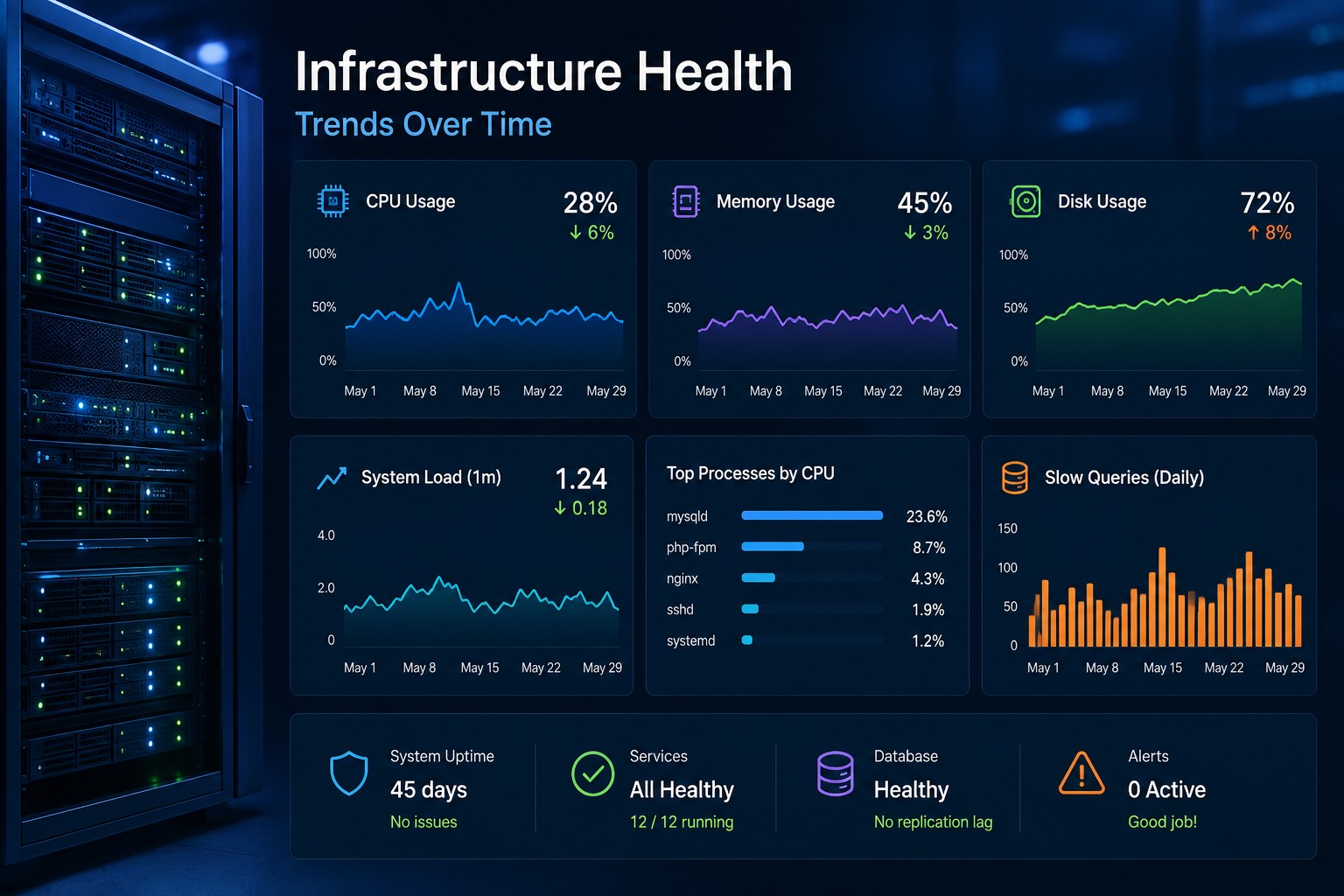
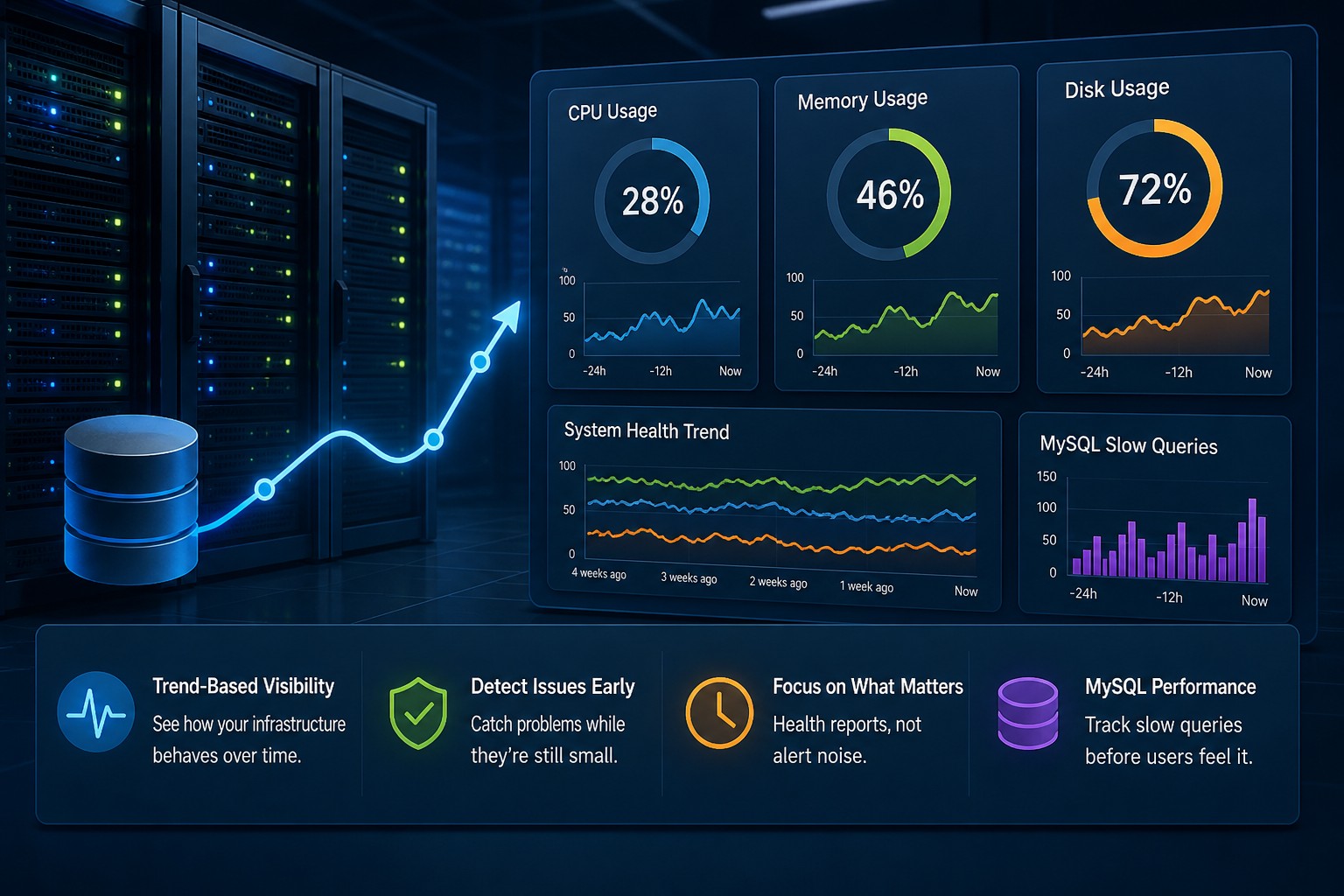
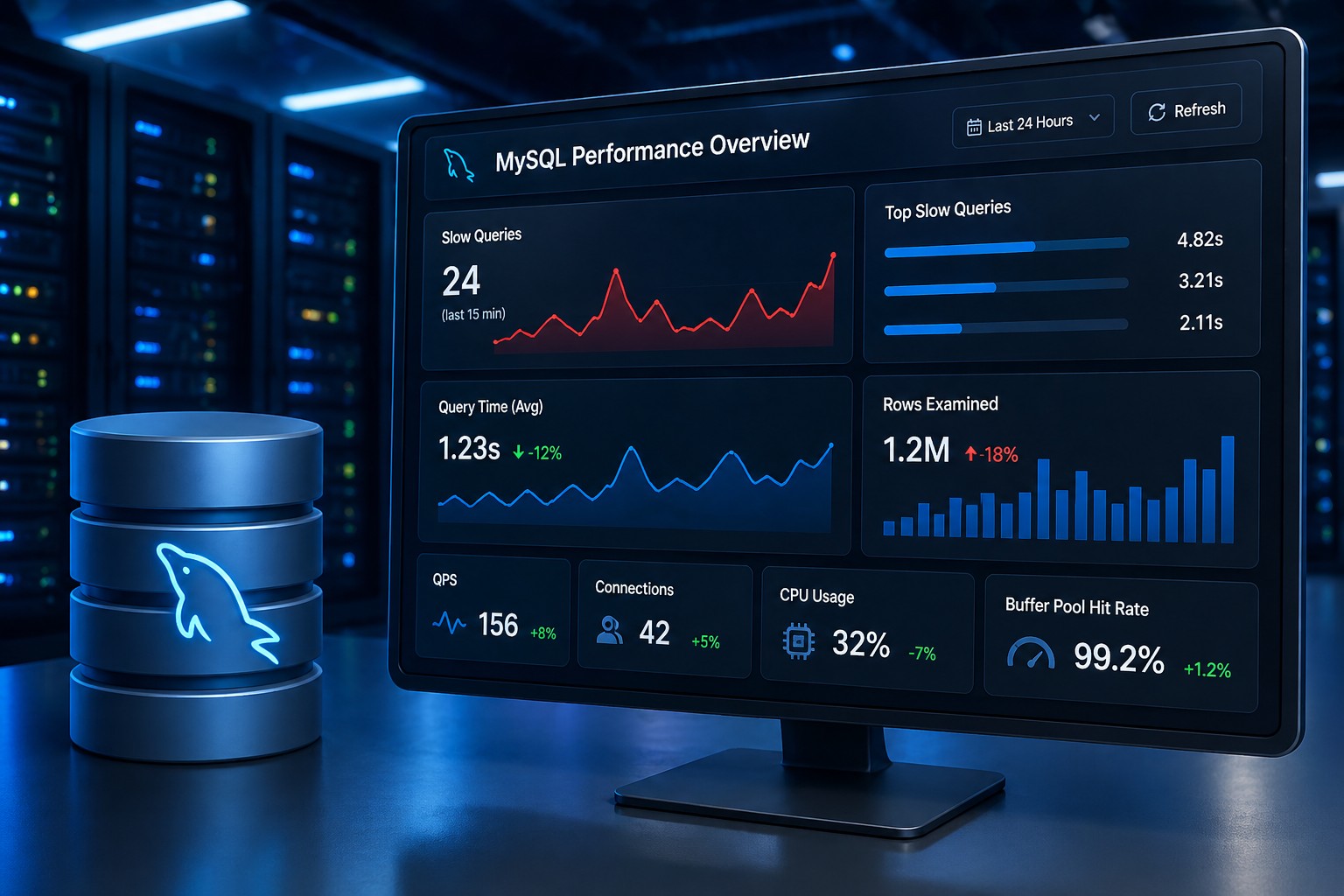
CPU saturation on Linux often becomes visible only after applications slow down. This article explains how to detect early warning signs using practical Linux commands, realistic thresholds, and operational troubleshooting patterns. It helps administrators distinguish harmless spikes from sustained contention. You'll also see how to identify likely causes before outages develop.
Read More