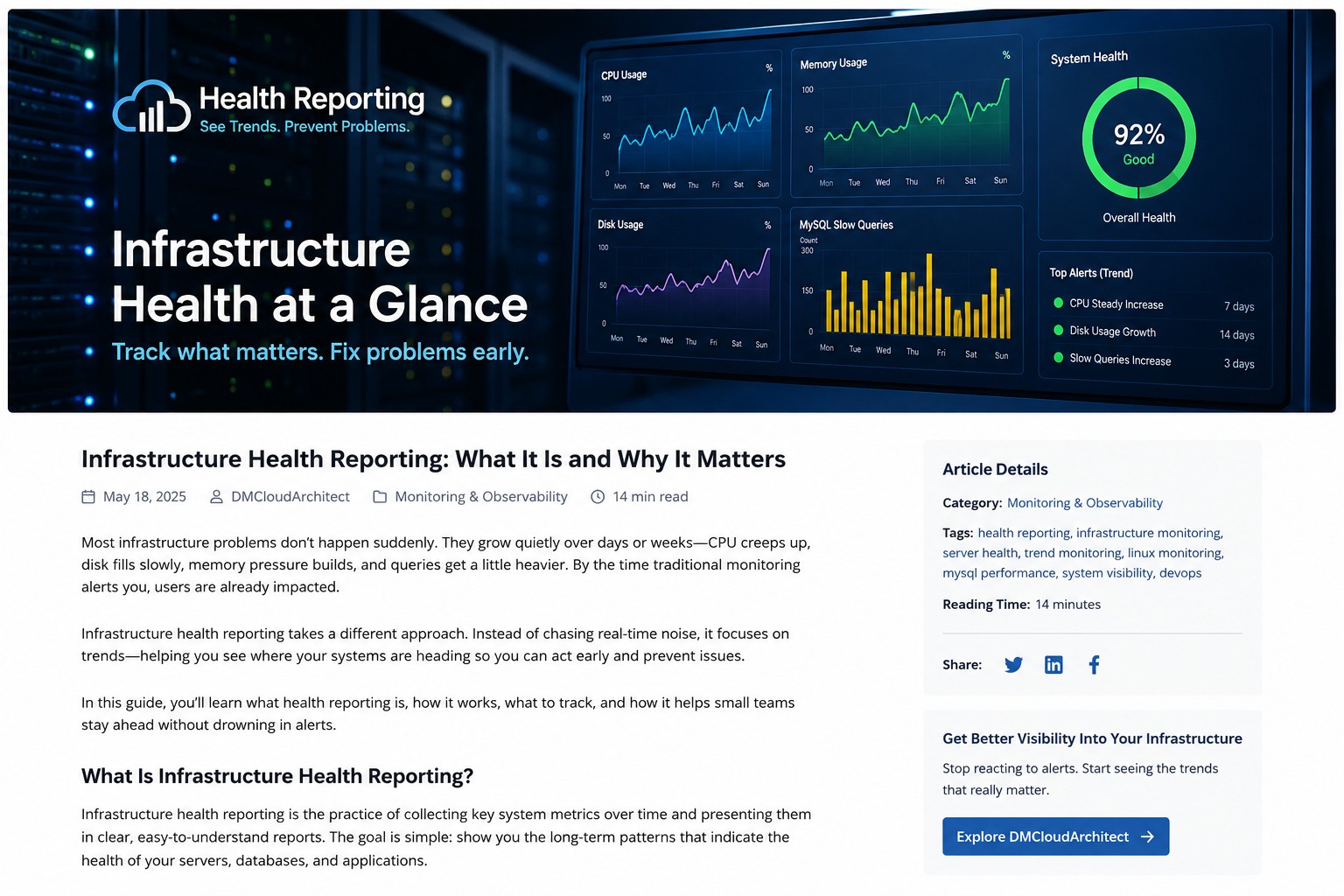
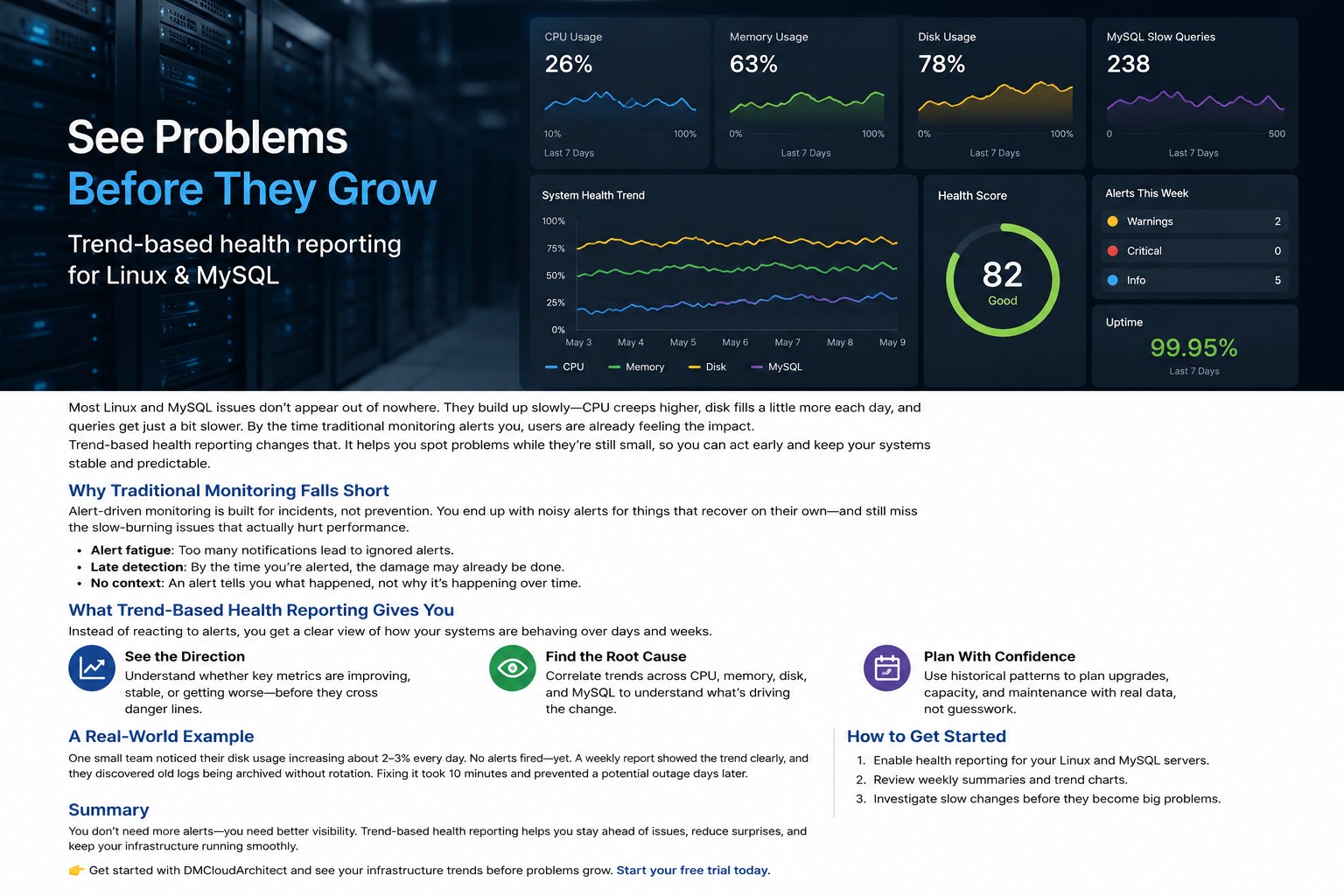
High CPU usage on a Linux server is not always a problem. Batch jobs, backups, and short traffic spikes can legitimately consume processor time. The real issue is sustained CPU saturation that starts affecting application response times, queue depth, and overall system stability.
A practical cpu saturation warning linux strategy helps administrators detect performance degradation before users start reporting slow applications. Whether you're managing Oracle workloads, MySQL services, web servers, or shared Linux infrastructure, early warning matters.
What CPU Saturation Actually Means
CPU saturation happens when runnable processes consistently compete for limited CPU resources. This is different from a brief utilization spike. Warning signs include elevated load averages, growing run queues, increased context switching, and user-visible latency.
Common indicators include:
- Load average consistently exceeding available CPU cores
- High %user or %system in
topormpstat - Steal time in virtualized environments
- Long application response times despite healthy memory and disk metrics
How to Detect CPU Issues Early on Linux
1. Check Real-Time CPU Pressure
top htop mpstat -P ALL 5
Look beyond a single CPU percentage. If multiple cores remain heavily utilized over repeated intervals, you may be seeing the start of cpu performance degradation on Linux.
2. Review Load and Run Queue Pressure
uptime vmstat 5
The r column in vmstat helps identify cpu bottleneck conditions. If runnable tasks regularly exceed available cores, contention is building.
3. Identify Process-Level Offenders
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head pidstat 5
This helps isolate runaway processes, inefficient queries, stuck workers, or misconfigured cron jobs.
Common Causes of CPU Performance Decline on Servers
- Database query inefficiency causing sustained compute pressure
- Application thread exhaustion creating excessive contention
- Kernel-heavy interrupt activity from networking or storage drivers
- Virtualization contention where host oversubscription introduces steal time
- Background maintenance jobs overlapping with production workloads
Practical CPU Saturation Warning Thresholds
Thresholds depend on workload, but these starting points are operationally useful:
- CPU utilization above 85% for 10–15 minutes
- Load average above core count for sustained periods
- Steal time above 5% in virtual instances
- Rapid increase in request latency combined with CPU pressure
Static thresholds alone are imperfect. Trend-based monitoring usually catches gradual degradation earlier than hard alerts.
Real-World Example
A Linux database server may show only 78% CPU utilization, which looks acceptable at first glance. But if load average is climbing, query response times are increasing, and runnable processes are queueing, the system is already under stress. This is exactly why teams that want to detect performance degradation CPU issues early track saturation patterns instead of a single utilization number.
Summary
Effective CPU monitoring is less about reacting to 100% utilization and more about recognizing saturation before service quality drops. If you need a structured way to review server performance trends across infrastructure, explore Infrastructure Health Reporting for a practical operational approach.