How to Detect Slow Infrastructure Issues Before They Become Outages
May 02, 2026
Mariusz Antonik
General
4 min read
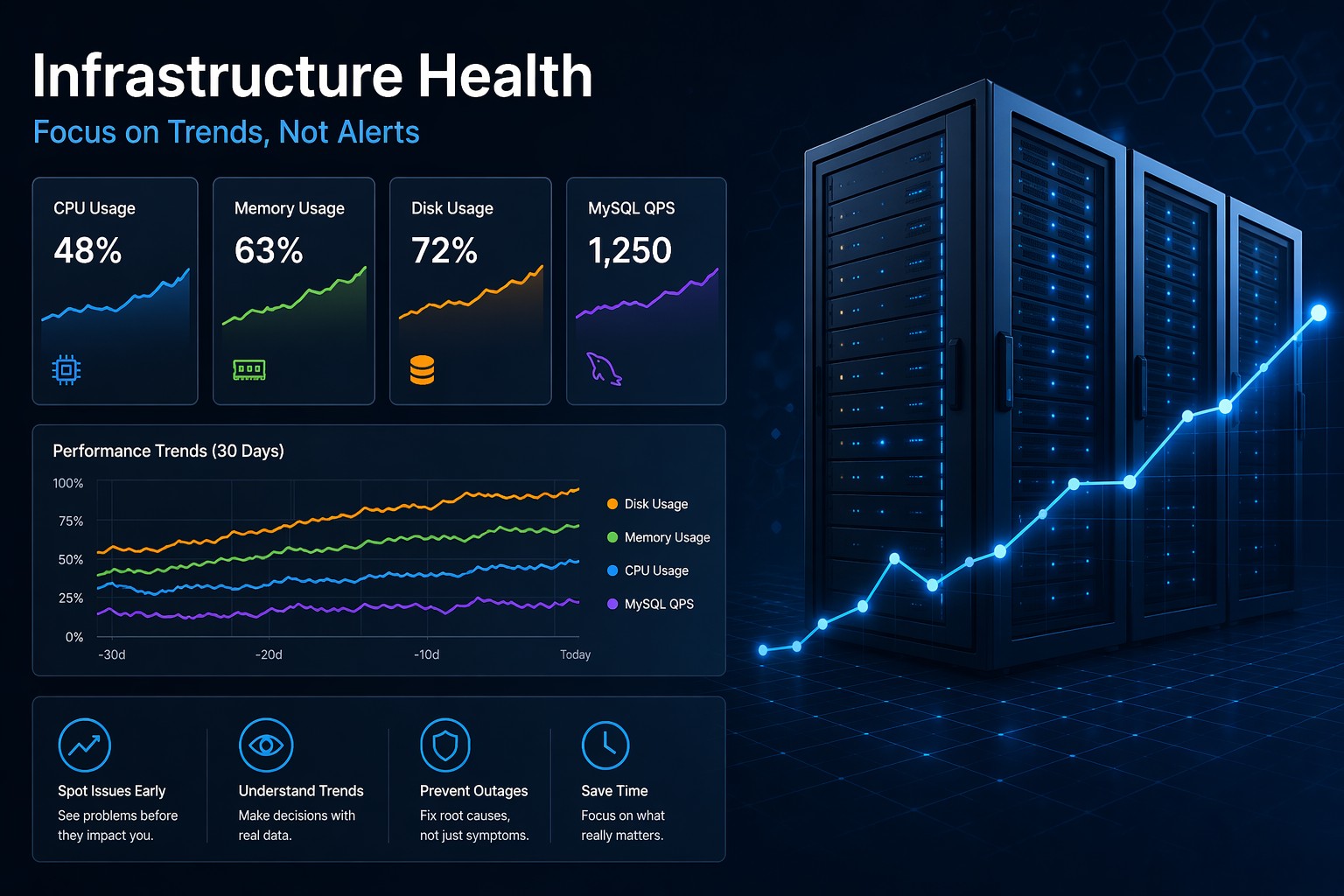
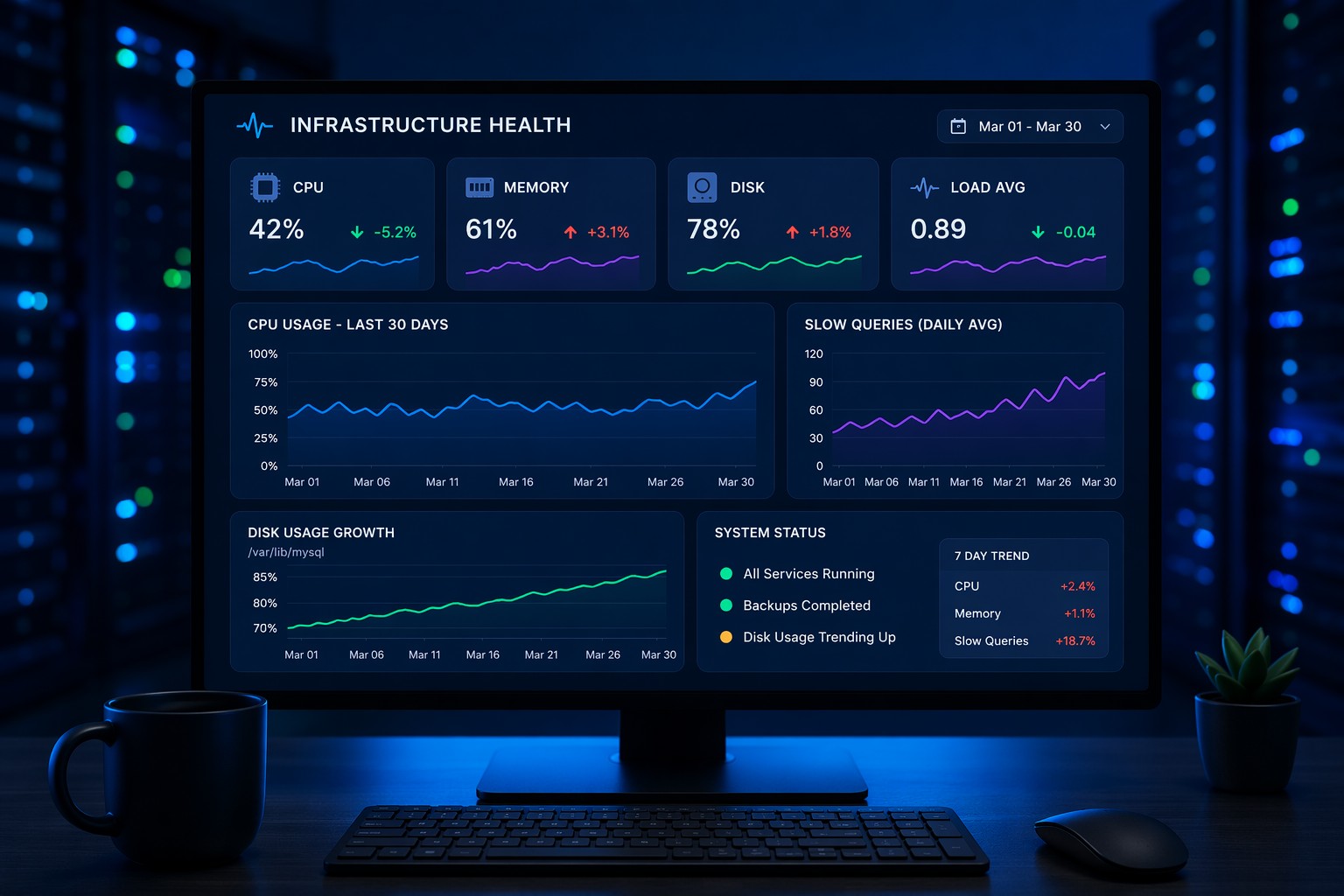
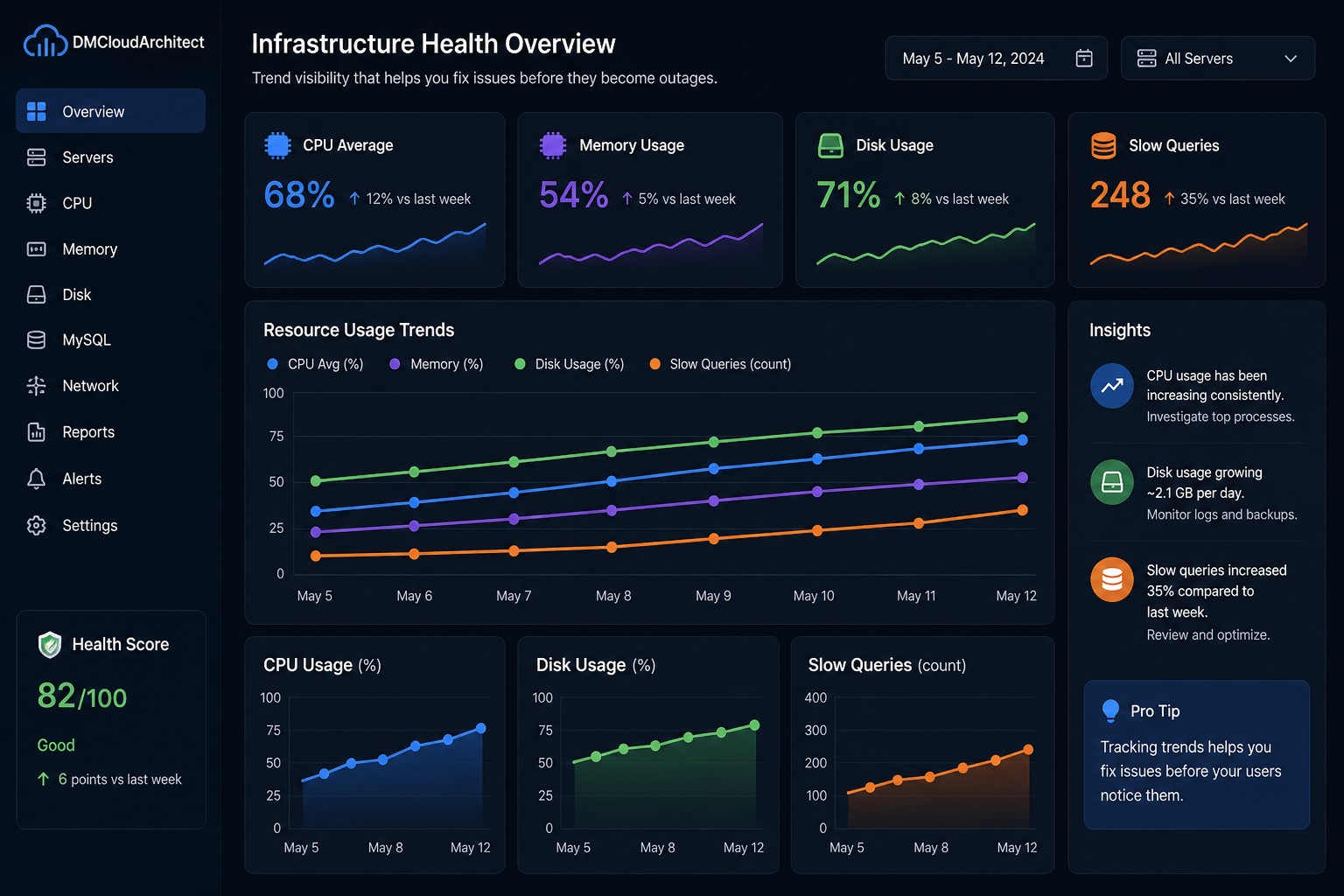
Most infrastructure problems don’t start as outages—they grow slowly over time. This article explains how to detect early warning signs like CPU creep, disk growth, and query slowdown before they become critical. You’ll learn practical ways to shift from reactive alerts to proactive visibility. Ideal for teams tired of firefighting and looking for real control over system health.
Read More