Infrastructure Health Early Detection: Stop Issues Before They Start
You don’t need more alerts.
You need better visibility over time.
Most infrastructure failures don’t happen suddenly. They build up slowly—CPU creep, memory pressure, disk latency, query slowdown. The problem is not detection. The problem is timing.
The Problem with Traditional Detection
Alerts only fire when thresholds are crossed.
By the time that happens:
- Performance is already degraded
- Users are already impacted
- Fixes become urgent instead of planned
This is reactive operations.
It doesn’t prevent problems. It just tells you when you're already in one.
What Early Detection Actually Means
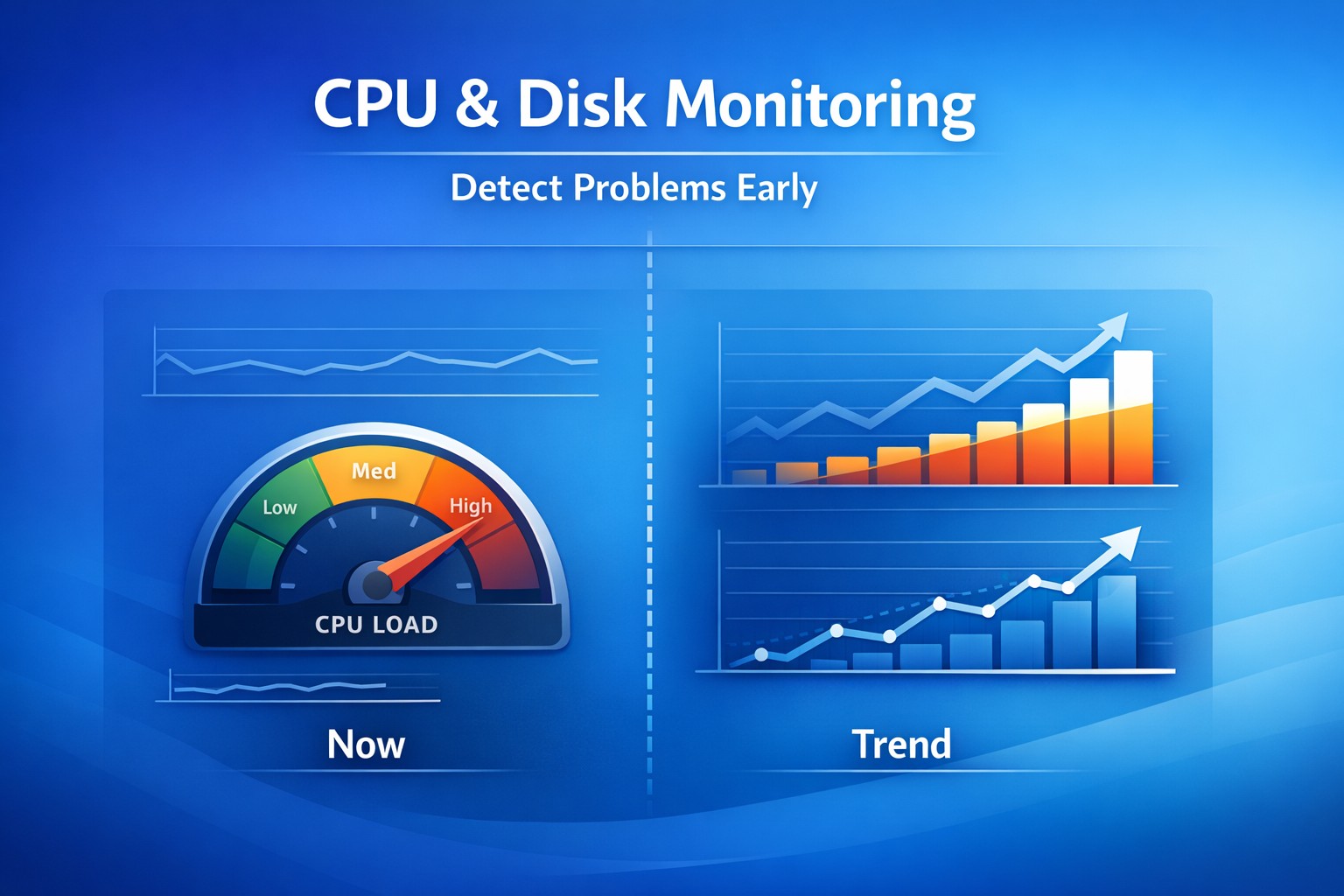
Early detection is not about speed.
It’s about trend visibility.
Instead of asking:
- “Is CPU high right now?”
You ask:
- “Has CPU been increasing every day for the last 2 weeks?”
That’s the difference.
Real Example: Gradual Degradation
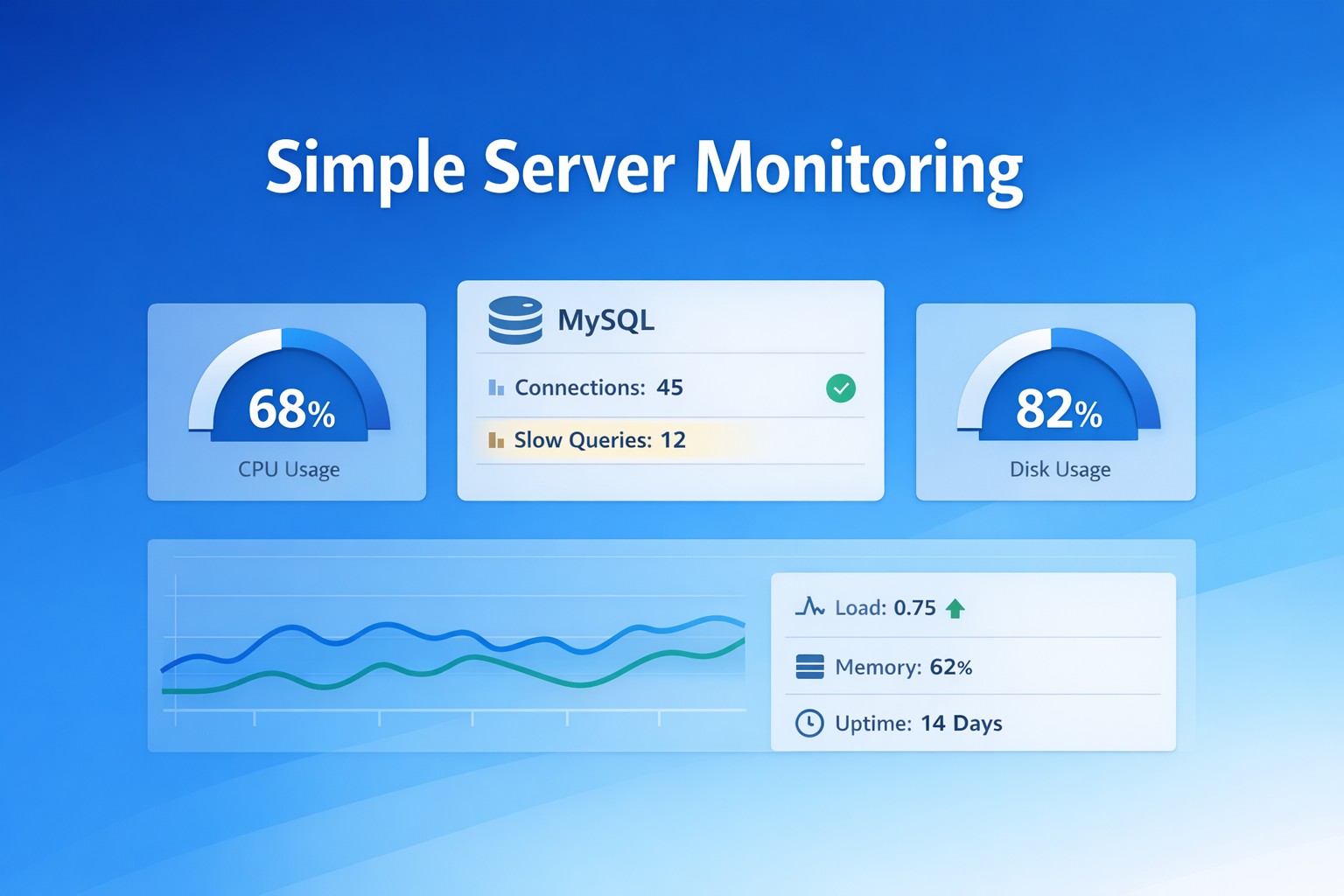
Let’s say your system looks fine today:
- CPU: 45%
- Memory: 60%
- Disk latency: normal
No alerts. Everything is “healthy.”
But over 30 days:
- CPU trend: 25% → 45%
- Memory trend: 40% → 60%
- Disk I/O slowly increasing
This is early-stage degradation.
Alerts won’t catch it.
Trend reporting will.
Why Infrastructure Health Reporting Works
Infrastructure health reporting focuses on:
- Daily snapshots
- Weekly comparisons
- Long-term trends
Instead of reacting to spikes, you identify patterns:
- Consistent growth
- Resource imbalance
- Slow performance drift
Key Signals to Watch
If you want early detection, track these trends:
- CPU usage over time (not peaks)
- Memory consumption growth
- Disk latency progression
- Database query execution trends
Individually, they look harmless.
Together, they tell the story of your infrastructure health.
Why Small Environments Need This Most
In small infrastructures:
- No dedicated SRE team
- Limited time for deep monitoring
- Issues are often discovered too late
Trend-based health reporting solves this by simplifying visibility.
No complex dashboards.
No alert fatigue.
Just clear, consistent signals over time.
From Reactive to Predictive
When you rely on alerts:
- You react to incidents
When you rely on trends:
- You prevent them
That’s the shift.
Early detection is not a feature.
It’s a mindset backed by visibility.
Conclusion
Infrastructure doesn’t fail instantly.
It degrades quietly.
If you can see the trend, you can stop the problem before it becomes critical.