Infrastructure Health vs Monitoring: Why Trends Matter More Than Alerts
Apr 24, 2026
Mariusz Antonik
General
4 min read
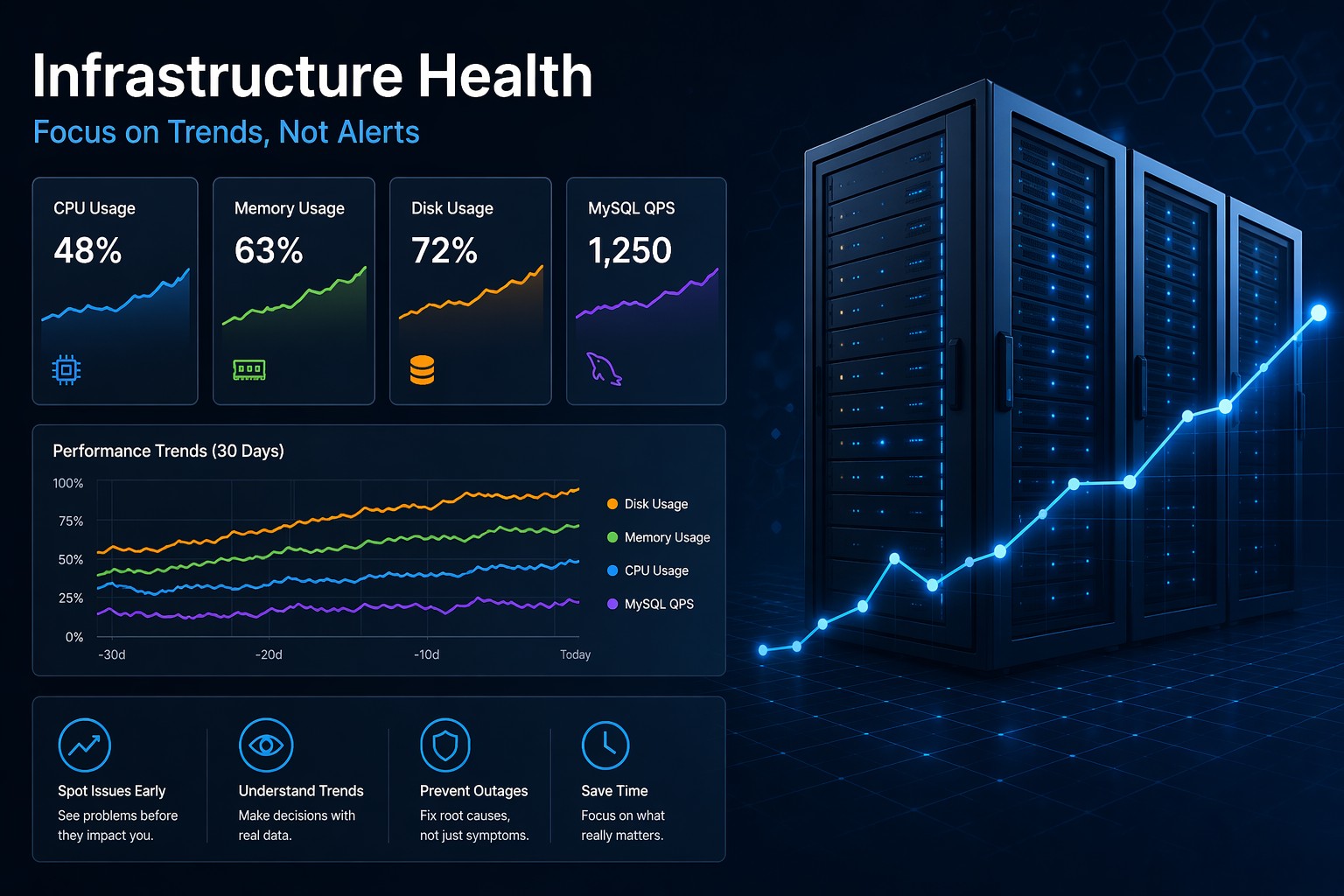
Most monitoring systems alert you only after something breaks. This article explains why infrastructure health reporting—focused on long-term trends—gives you earlier, more actionable insights. You’ll see how small issues grow over time and how to catch them before they turn into outages. If you manage servers or databases, this approach can simplify your stack and improve reliability.
Read More