If you're running a small production server, chances are you're juggling multiple responsibilities at once. You don’t have a dedicated DevOps team, and you probably don’t want one just to keep an eye on CPU graphs. But here’s the problem: issues don’t show up all at once. They build slowly—until one day, your server is suddenly “slow” or worse, down.
That’s why learning how to monitor a small production server properly matters. Not with noisy alerts or complex tools—but with clear, simple visibility into what’s actually changing over time.
Why Small Server Monitoring Is Different
Most monitoring tools are built for large-scale systems. They assume you have time to tune alerts, manage dashboards, and respond instantly. That’s not how small infrastructure works.
In a small setup, you need something lighter. Something that tells you:
- What’s trending upward
- What’s slowly degrading
- Where capacity is being consumed over time
Here’s the thing… small servers don’t usually fail because of sudden spikes. They fail because of gradual pressure—like disk filling up or queries getting slower week after week.
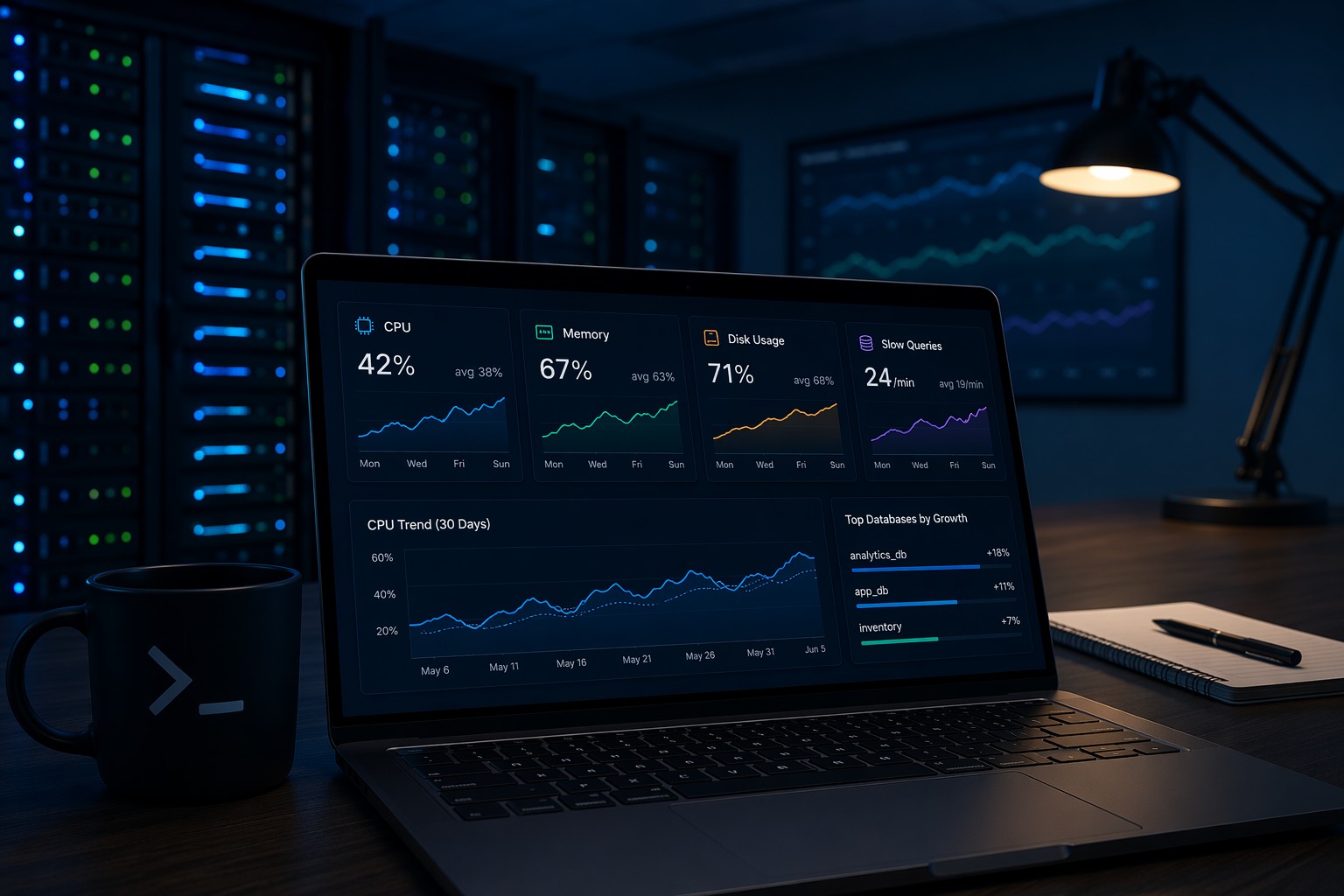
What You Should Actually Monitor
When setting up small infrastructure monitoring, focus on a few key signals. You don’t need dozens of metrics—just the right ones.
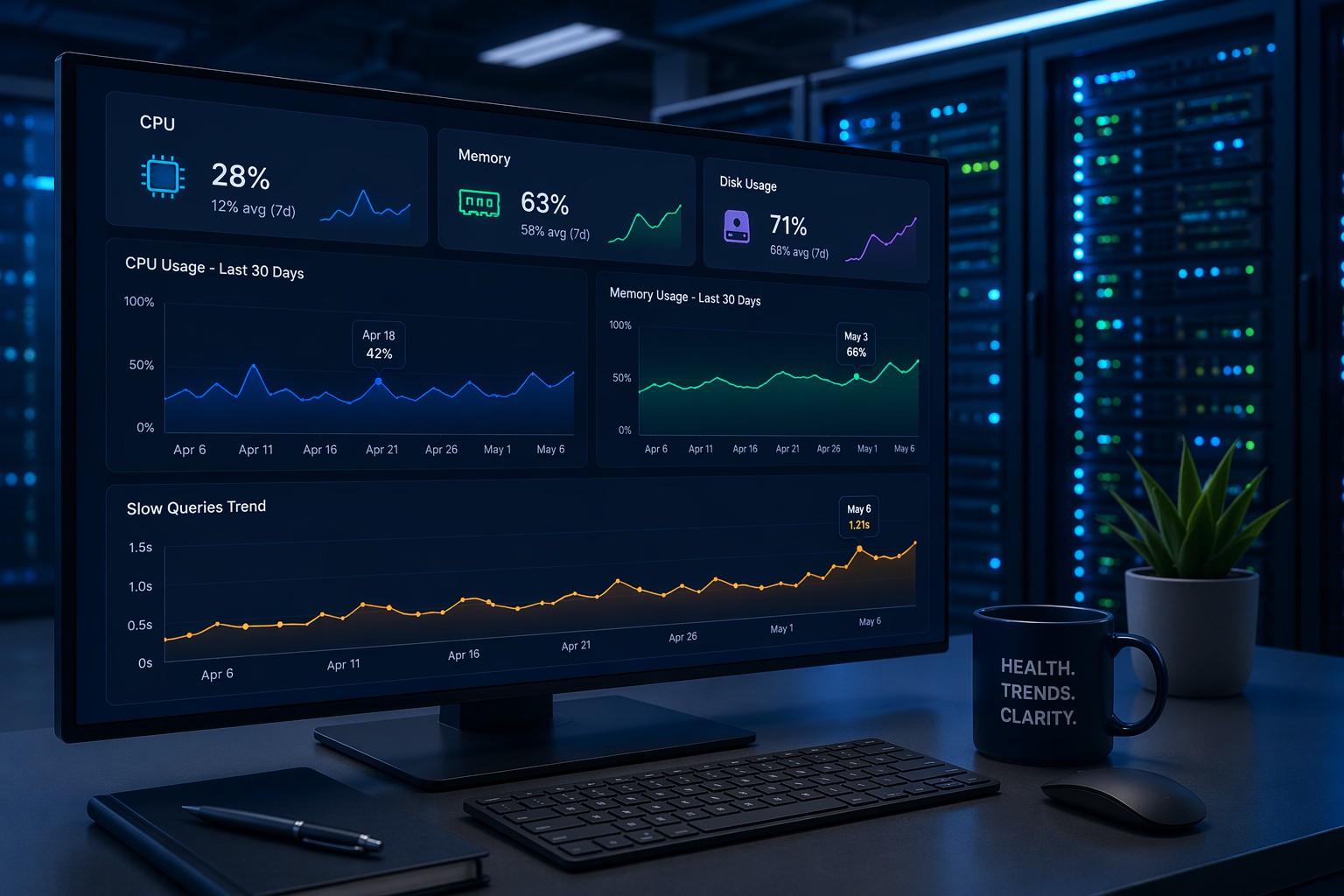
CPU Usage Trends
Short spikes are normal. What matters is whether your baseline is increasing. If your average CPU usage was 20% last month and now it’s consistently at 50%, something changed.
Memory Consumption
Memory issues often creep in slowly. A service that wasn’t leaking before might start consuming more RAM after an update.
Disk Usage Growth
This is one of the most common issues. Logs grow. Backups accumulate. Temporary files never get cleaned.
Like a slow leak, disk usage can go unnoticed until it’s critical.
Database Performance
If you’re running MySQL or similar, keep an eye on slow query trends—not just individual slow queries.
But this is where it matters… one slow query isn’t the issue. A pattern of gradually increasing query time is.
Avoid Alert Fatigue
Many teams try to monitor small servers the same way large enterprises do—with alerts for everything.
The result?
- Too many notifications
- Alerts ignored over time
- Real issues buried in noise
Instead of reacting to every spike, focus on understanding trends. You don’t need to know every second something changes—you need to know when something is clearly getting worse.
A Practical Example
Let’s say you’re running a small production app on a single VM.
At first, everything looks fine. CPU is stable, memory usage is predictable, and disk usage is low.
Over the next few weeks:
- Disk usage grows from 40% to 75%
- Slow queries increase slightly every day
- Memory usage creeps up after each deployment
None of these trigger an alert. But together, they tell a story.
So what does this mean in practice?
You have early warning signs. You can clean up logs, optimize queries, or scale before users feel anything.
Keep It Lightweight
You don’t need a full observability stack to monitor a small production server. In fact, that often creates more problems than it solves.
A lightweight monitoring solution should give you:
- Daily or weekly trend visibility
- Simple dashboards focused on key metrics
- Clear signals instead of constant alerts
The goal isn’t to watch everything in real-time. It’s to understand how your system behaves over time.
Summary
To monitor a small production server effectively, you need to shift your mindset. Focus less on reacting instantly and more on understanding patterns.
Watch trends in CPU, memory, disk, and database performance. Avoid alert overload. And most importantly, look for slow changes before they turn into real problems.
If you want a simpler way to see how your infrastructure is evolving without dealing with complex monitoring stacks, you can explore a lightweight approach here: https://health.dmcloudarchitect.com/