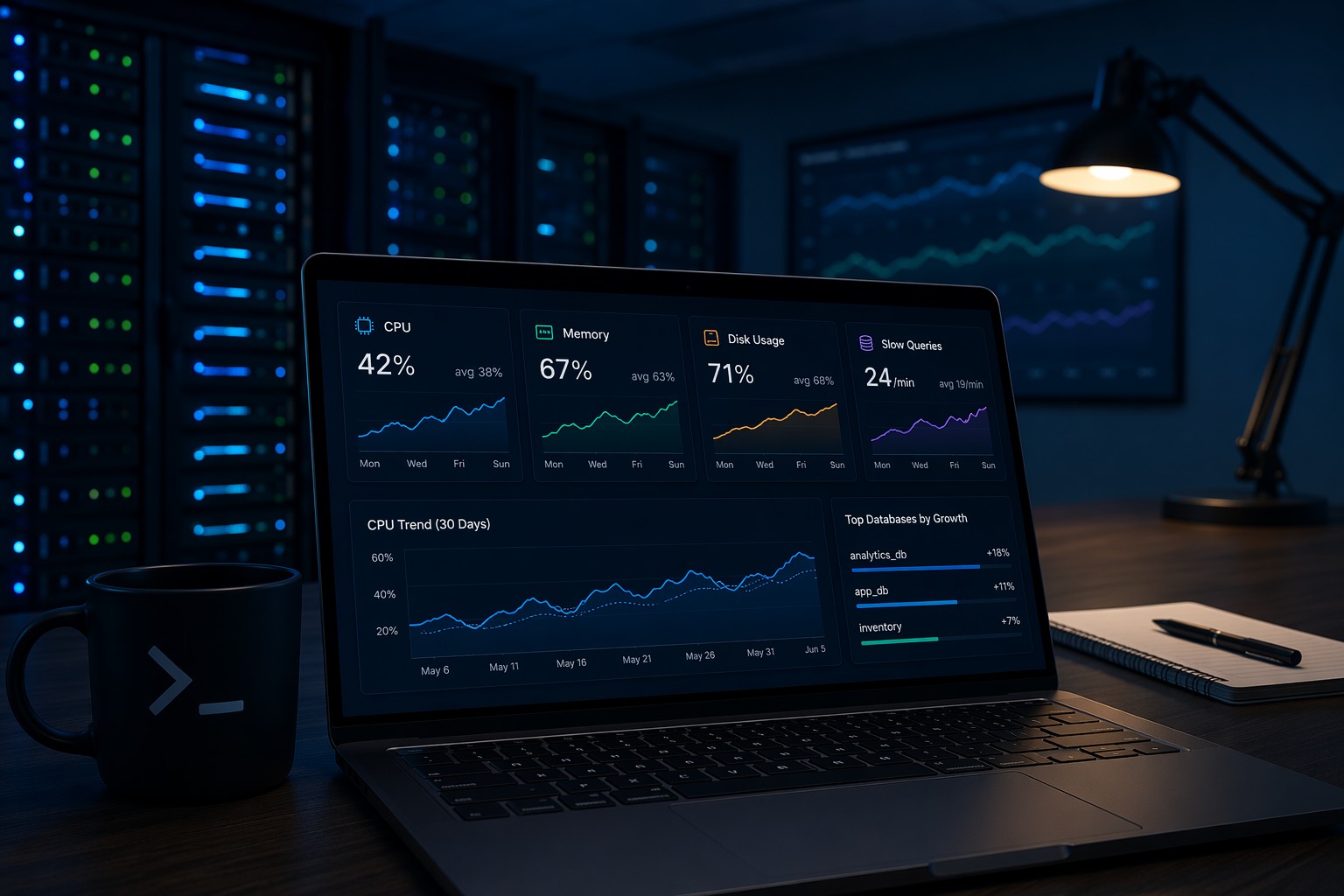
Most teams don’t actually lack monitoring. They lack clarity. You might already have alerts, dashboards, and logs—but when someone asks, “How healthy were our servers this week?” the answer isn’t obvious.
That’s where a server health weekly report becomes useful. It shifts your focus from reacting to individual alerts to understanding how your systems behave over time. Instead of noise, you get patterns. And those patterns are where real problems—and real improvements—live.
Why Weekly Reporting Changes How You See Infrastructure
Here’s the thing: most infrastructure issues don’t appear suddenly. They build slowly.
A disk fills up over weeks. CPU usage creeps up as traffic grows. Slow queries increase gradually until performance drops. Alerts only fire when something crosses a threshold—but by then, the problem has already been developing for days or weeks.
A structured infrastructure monitoring report helps you step back and see the bigger picture. Instead of asking “What broke?”, you start asking “What’s trending in the wrong direction?”
What a Server Health Weekly Report Should Include
A good server health reporting approach doesn’t try to include everything. It focuses on signals that actually indicate long-term health.
1. CPU Trends
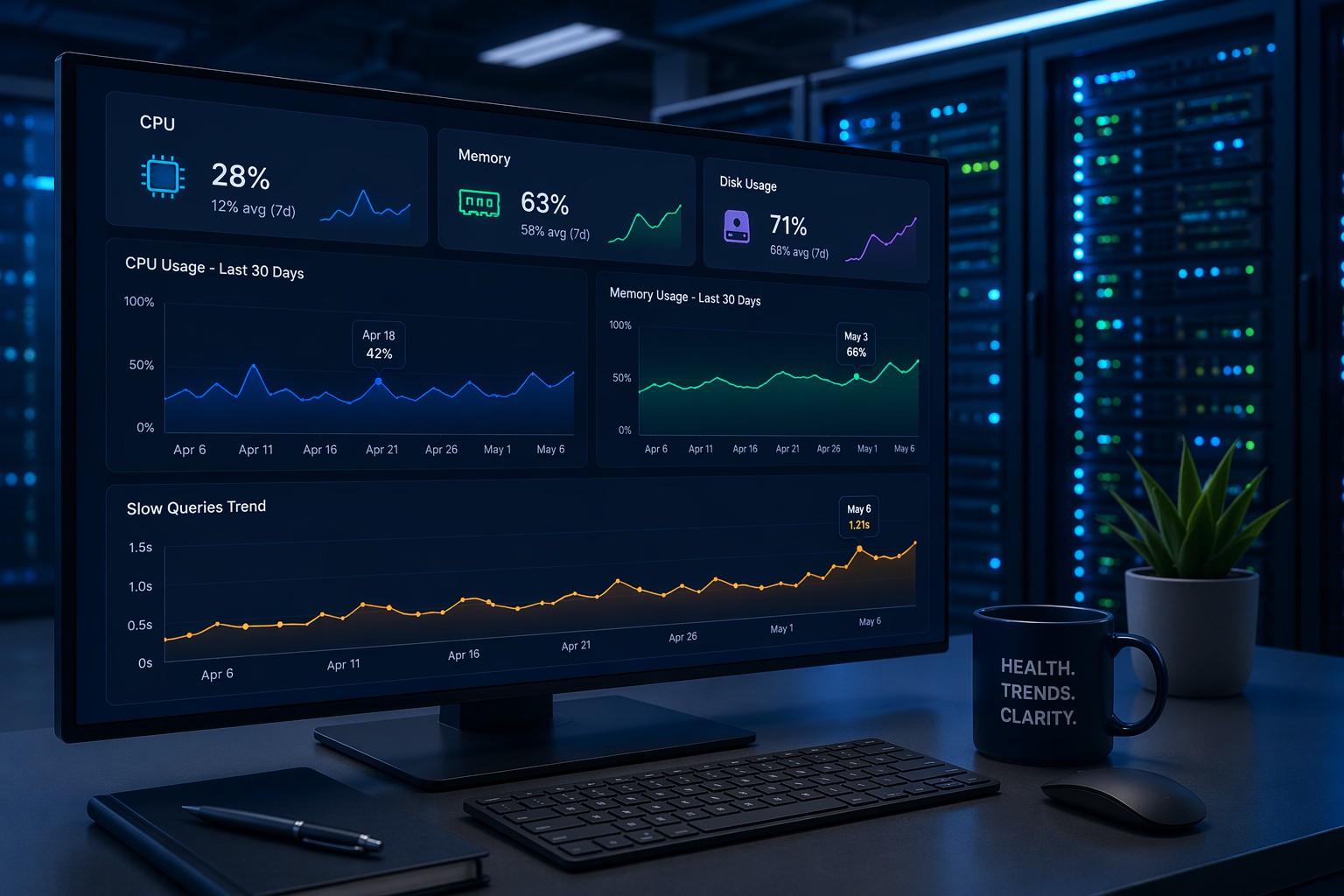
Look at average and peak CPU usage across the week. One spike isn’t a concern—but a steady increase is.
For example, if your average CPU moved from 35% to 55% over two weeks, that’s a signal worth investigating before it becomes saturation.
2. Memory Usage Patterns
Memory tells a different story. Gradual growth may indicate leaks, inefficient caching, or growing workloads.
Weekly views make it easier to spot patterns that daily dashboards hide.
3. Disk Utilization and Growth
This is one of the most common slow-burn problems. A disk at 70% isn’t urgent—but if it’s growing 5% per week, you have a timeline to act on.
4. Database and Query Performance
Track slow queries, query volume, and execution time trends. A rising number of slow queries often shows up before users notice performance issues.
5. Error Rates and Service Stability
Even small increases in error rates can signal instability. Weekly aggregation helps separate noise from real degradation.
From Raw Metrics to Meaningful Insights
Collecting metrics is easy. Turning them into insights is where most teams struggle.
But this is where it matters: your report shouldn’t just show numbers—it should highlight changes.
- What increased compared to last week?
- What stayed stable?
- What is trending toward a limit?
This transforms a simple system health reporting document into something actionable.
A Simple Weekly Workflow You Can Follow
You don’t need a complex setup to start. A lightweight weekly process is enough.
- Collect metrics from your infrastructure health dashboard
- Compare against the previous week
- Highlight 2–3 notable changes
- Add short notes explaining possible causes
- Share with your team
The goal isn’t perfection. It’s consistency.
Real-World Example: The Slow CPU Creep
Let’s say your application server shows no alerts. Everything looks “fine.”
But your weekly report tells a different story:
- Week 1: average CPU 32%
- Week 2: average CPU 41%
- Week 3: average CPU 52%
No alert triggered. No incident occurred. But you can clearly see a trend.
This could be growing traffic, inefficient queries, or a background job behaving differently. Without a weekly view, you’d only notice when CPU suddenly hits 90%.
This is exactly the kind of visibility infrastructure health reporting is meant to provide.
Why Small Teams Benefit the Most
If you’re running a small or mid-sized infrastructure, you probably don’t have a dedicated observability team. You also don’t have time to chase every alert.
A weekly infrastructure health dashboard summary gives you a manageable way to stay in control without adding complexity.
Instead of reacting all day, you spend a focused hour each week understanding your systems.
Common Mistakes to Avoid
- Too many metrics: focus on trends, not everything available
- No comparisons: a number alone has no meaning without context
- Inconsistent reporting: skipping weeks breaks visibility
- No action: reports should lead to decisions, not just documentation
Summary
A server health weekly report helps you move from reactive monitoring to proactive infrastructure management. Instead of waiting for alerts, you start identifying patterns early—when they’re still easy to fix.
Over time, this approach builds a clearer understanding of how your systems behave and where they’re heading.
If you want a simpler way to generate consistent reports without adding more monitoring noise, take a look at Infrastructure Health Reporting and see how it fits into your workflow.