How to Track CPU Trend Monitoring on Linux Servers
Apr 19, 2026
Mariusz Antonik
Server Health
6 min read
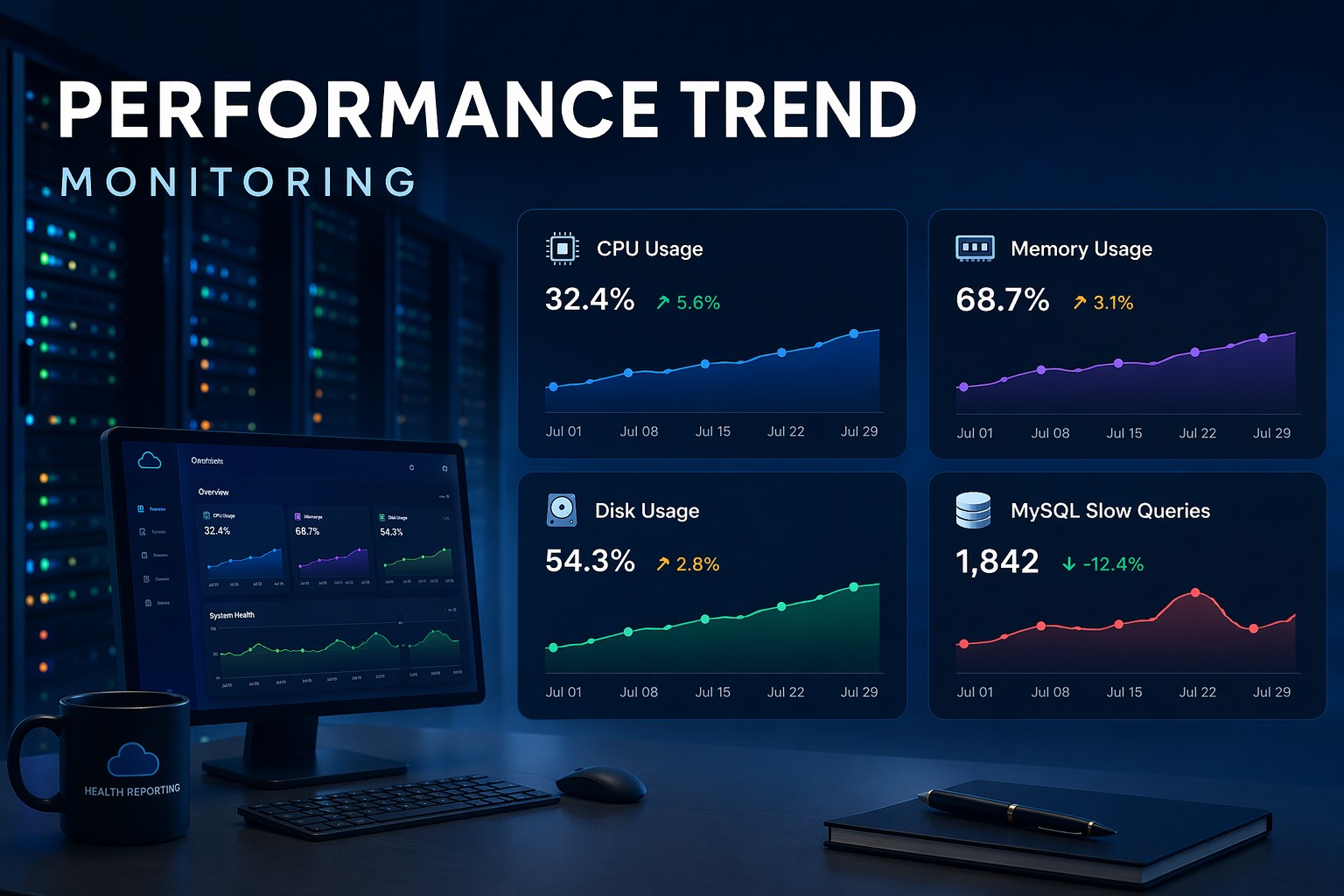
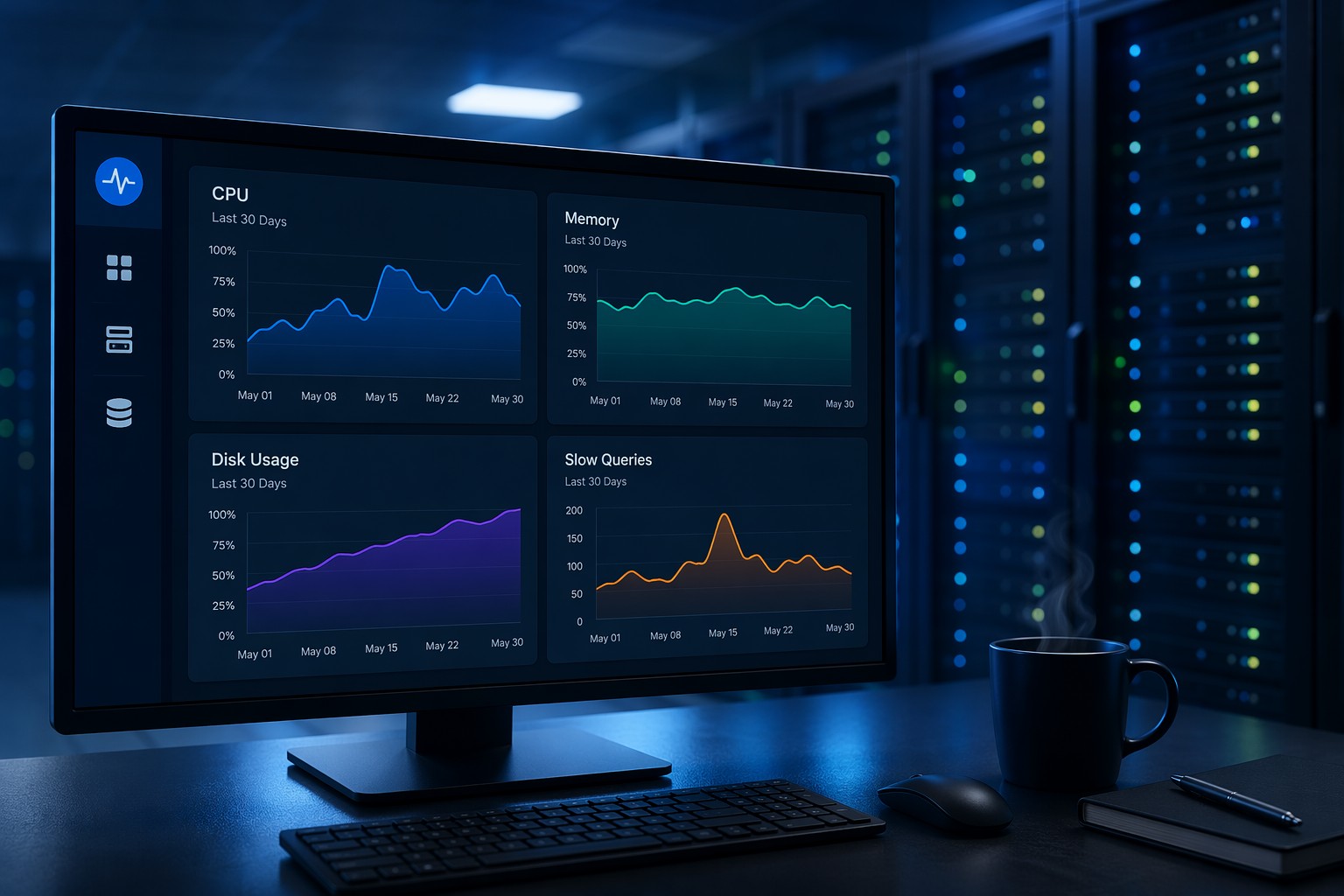
Most monitoring tools tell you when something is already broken, but cpu trend monitoring on Linux is about spotting problems before that moment arrives. By tracking CPU usage history over days and weeks, small infrastructure teams can identify rising load patterns, unexpected overnight spikes, and gradual utilization growth that would never trigger a real-time alert. This guide walks through practical tools including sar, vmstat, and Prometheus to capture and review CPU utilization trends on Linux servers. You will come away with a straightforward approach to weekly health reviews that replaces reactive firefighting with informed capacity planning.
#Capacity Planning
#CPU Monitoring
#infrastructure health
#Linux monitoring
#server health
#Trend Monitoring
Read More