Minimal Linux Monitoring Setup for Small Teams
May 09, 2026
Mariusz Antonik
Infrastructure Monitoring
6 min read
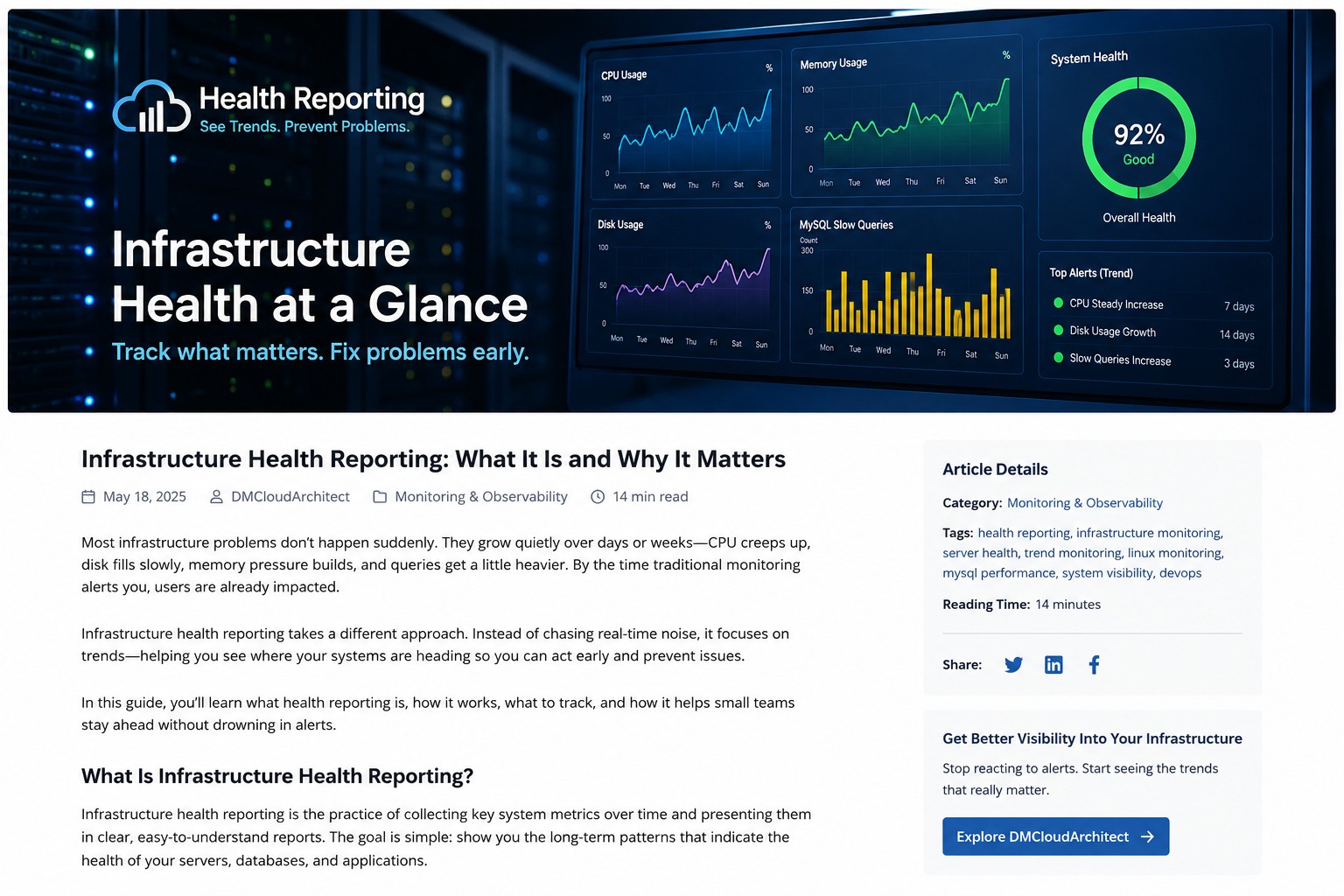
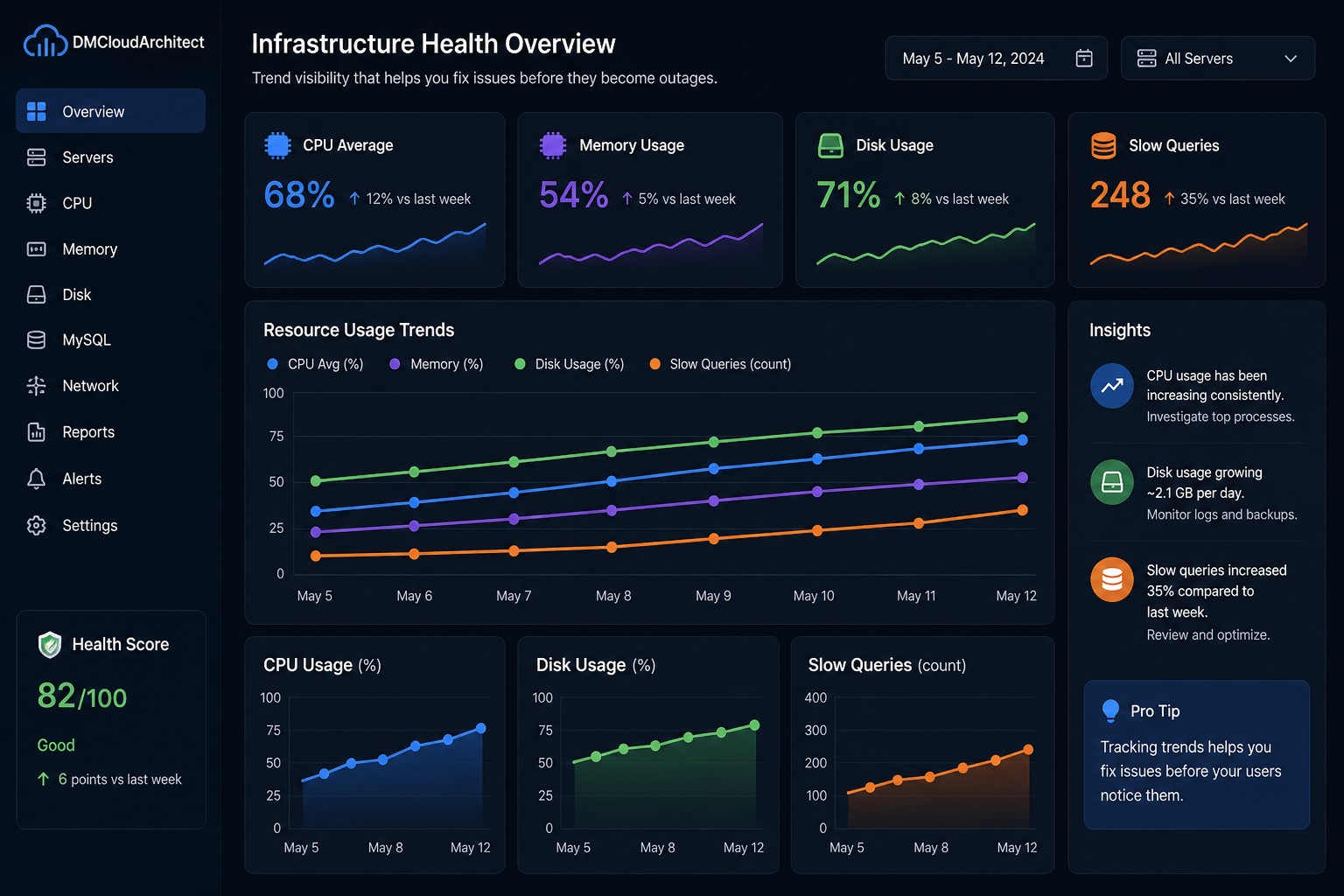
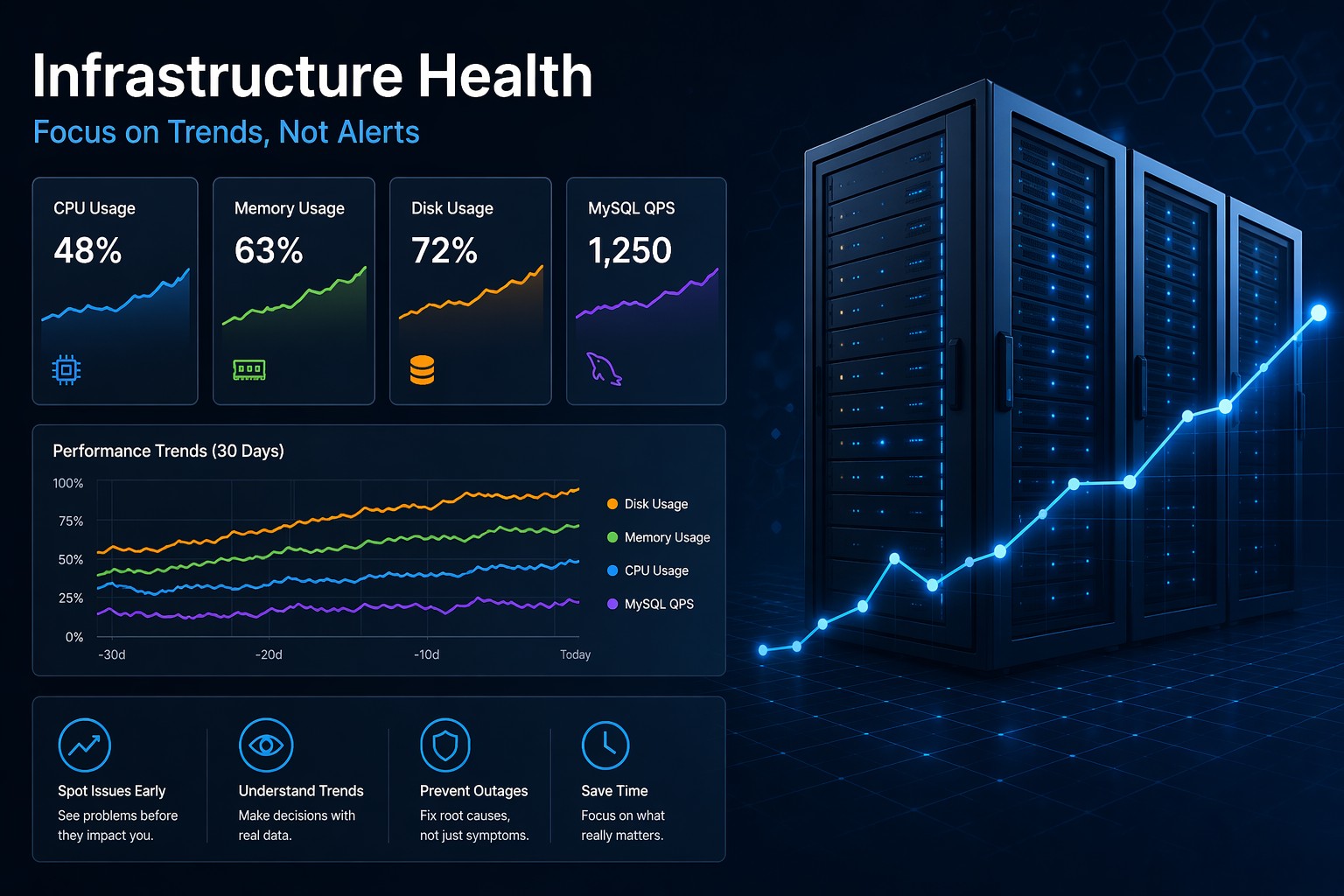
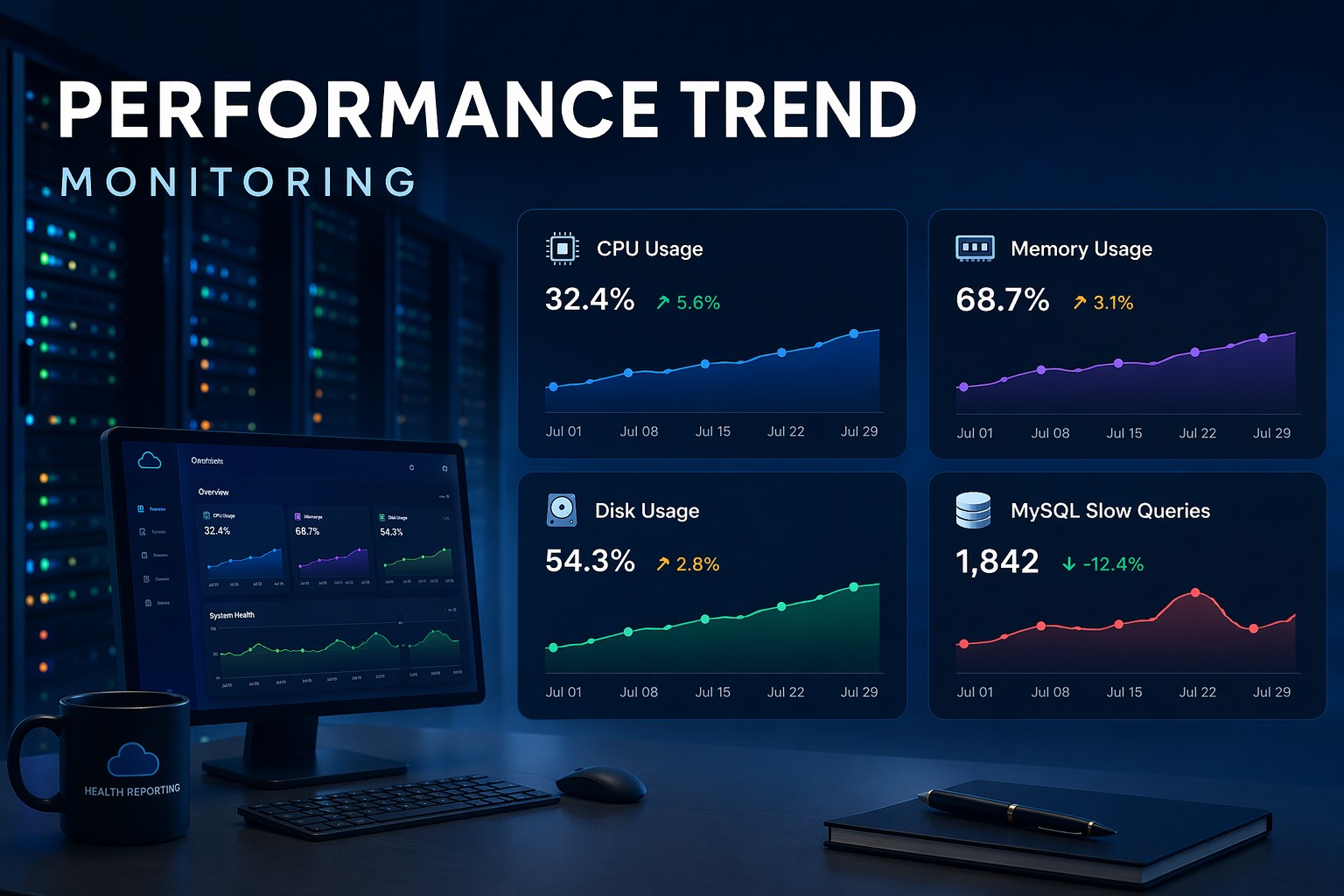
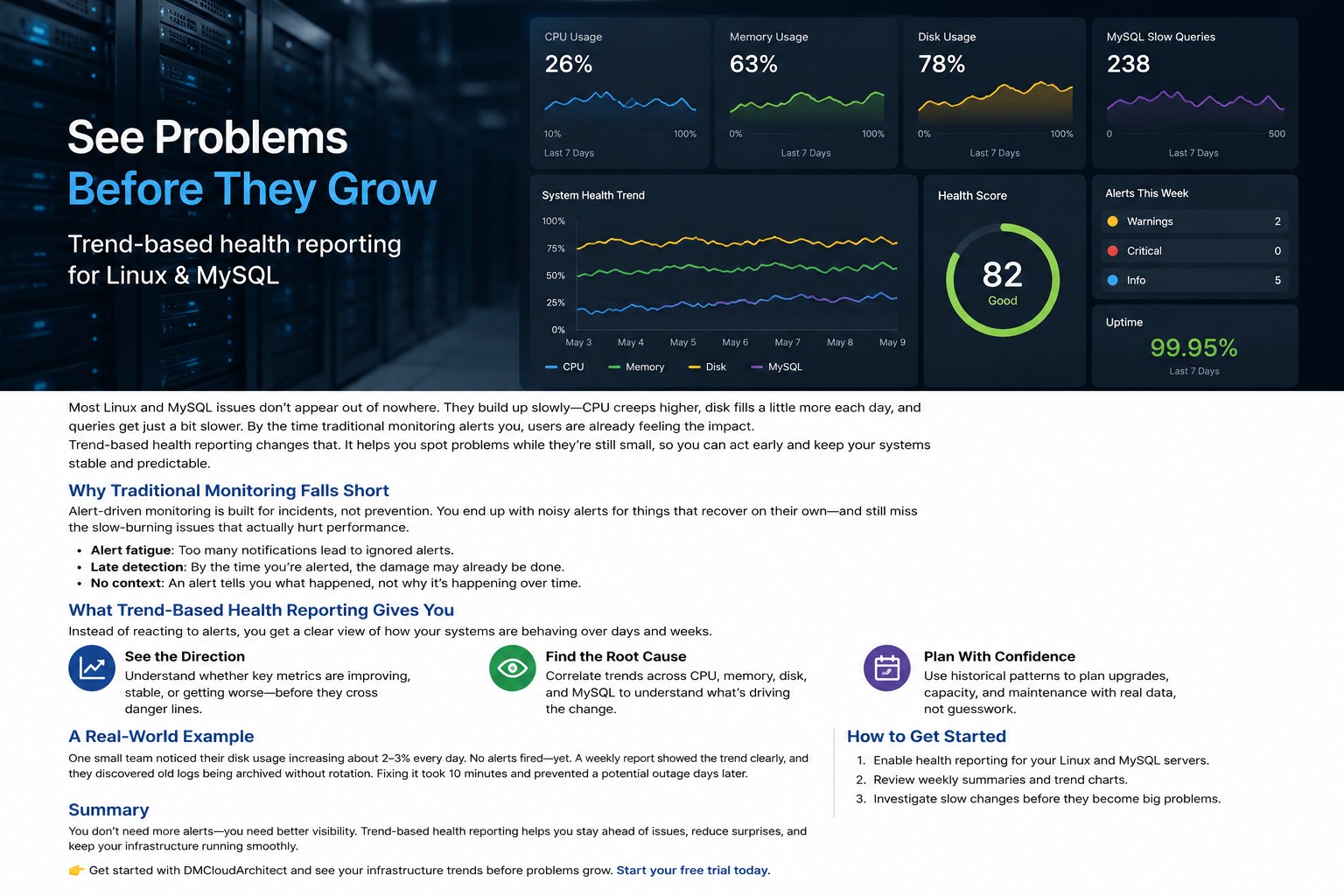
Many small infrastructure teams need better visibility into Linux server health without maintaining complex observability stacks. This article explains how to build a minimal linux monitoring setup focused on trends, stability, and practical operational awareness. You will learn what metrics matter most, why lightweight monitoring often works better for small environments, and how trend-based reporting helps catch issues before outages happen. The guide also covers practical examples, common mistakes, and ways to reduce alert fatigue while keeping systems predictable.
#infrastructure monitoring
#lightweight monitoring
#Linux monitoring
#linux servers
#MySQL monitoring
#System Health
Read More