How to Build a Bash Script for Disk Monitoring on Linux
Apr 19, 2026
Mariusz Antonik
Server Health
4 min read
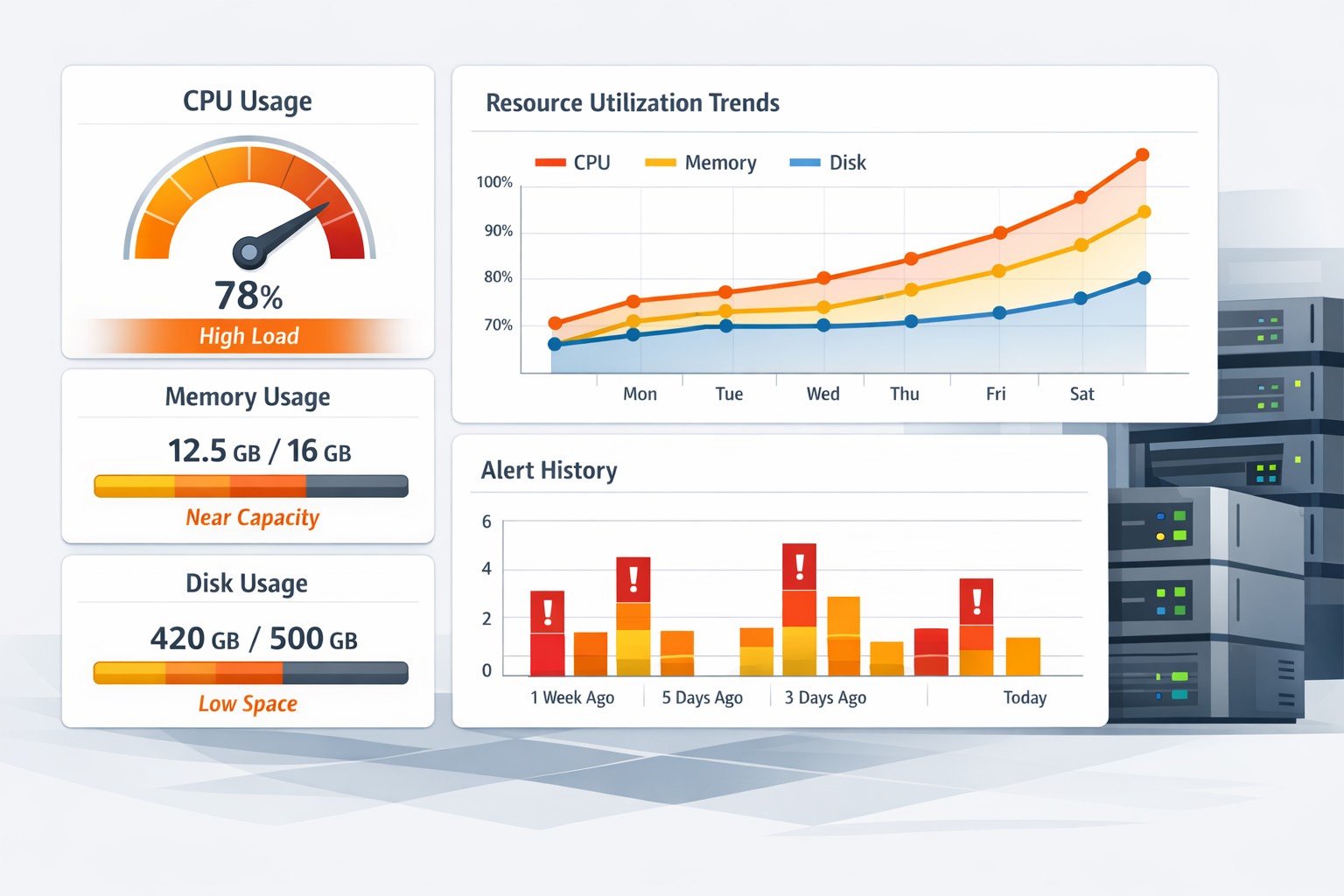
Disk space problems tend to build slowly, and by the time a threshold alert fires, the damage is often already done. A bash script for disk monitoring gives you a lightweight, automatic way to check disk usage across your Linux servers on a regular schedule. This guide covers building a working script from scratch, scheduling it with cron, checking inode usage, and making the log output useful over time.
#Capacity Planning
#Disk Monitoring
#Health Reporting
#infrastructure monitoring
#Linux monitoring
#server health
Read More